딥러닝 네트워크에서 초기 가중치를 설정하는 가중치 초기화 방법에 대한 정리
가중치 초기화 (Weight Initialization)
- 딥러닝을 학습할 때 초기 가중치는 매우 중요한 역할을 한다. 초기 가중치에 따라 가중치의 학습 방향이 달라지며,. 초기 가중치가 너무 크거나 작으면 기울기(gradient)가 너무 커지거나 작아져서 기울 폭주나 소실(Gradients Vanishing & Exploding) 문제가 발생할 수 있다.
가중치 초기화 방법
Zero Initialization
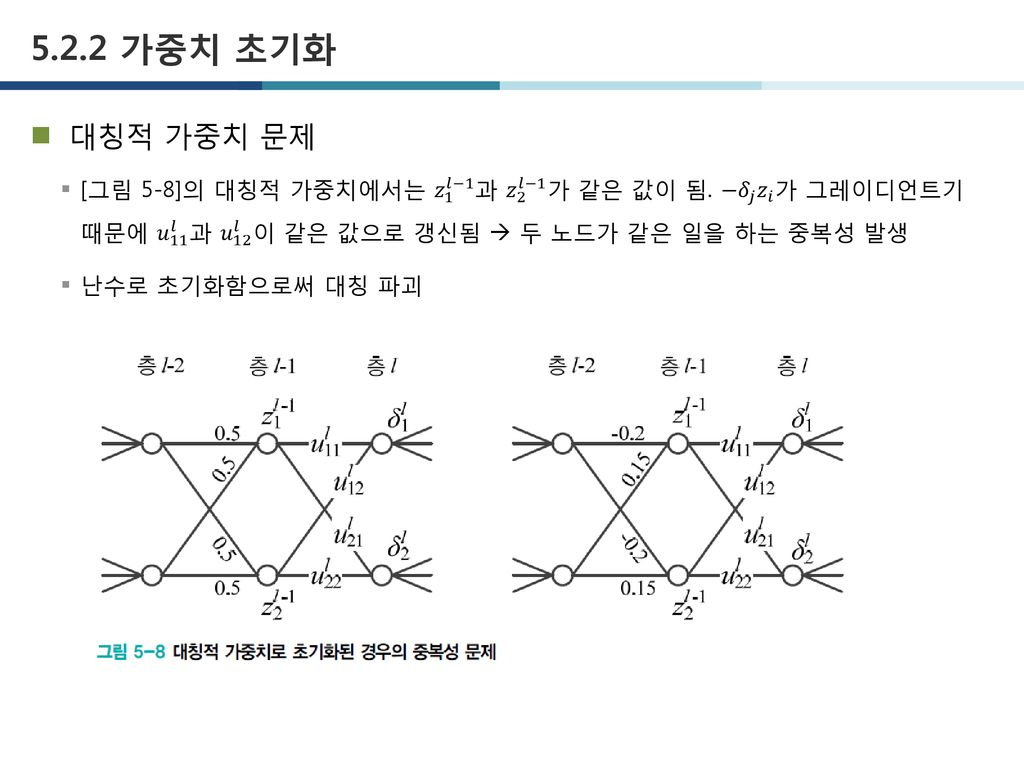
- 만약 모든 가중치를 0으로 초기화 한다면 어떻게 될까 → 모든 가중치들이 같은 방식으로 업데이트되며 학습이 제대로 안됨.
- 대칭적 가중치 문제가 발생하기 때문. 신경망 노드의 파라미터가 모두 동일하다면 여러 개의 노드로 신경망을 구성하는 의미가 사라진다.
Random Initialization
- 대칭적 가중치의 문제를 막기위해 가중치를 랜덤으로 초기화 한다.
정규분포 초기화
- 정규분포를 이루는 값을 각 가중치에 배정하여 모두 다르게 설정할 수 있다.
- 표준편차를 다르게 설정하면서 정규분포로 가중치를 초기화한 신경망의 활성화 함수 출력 값을 시각화함. 신경망은 100개의 노드를 5층으로 쌓았다.
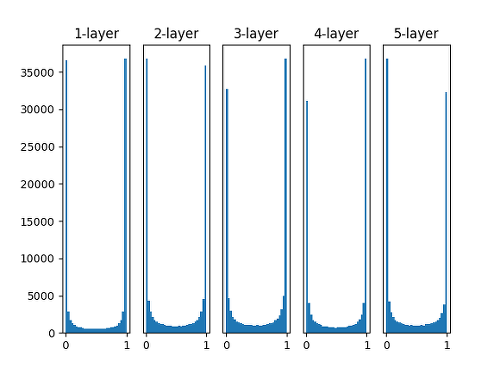
- 활성화 함수로 Simoid를 사용하고 평균 0, 표준편차 1인 정규분포를 따르도록 가중치를 랜덤 초기화함
- 아래 그림과 같이 각 레이어의 활성화 값이 0과 1에 치우져서 분포됨(표준편차가 크기 때문에) →
- sigmoid 함수는 출력이 0에 가까워지거나 1에 가까워지면 그 미분 값은 0에 가까워지게 되므로 Vanishing Gradients 문제를 야기함.
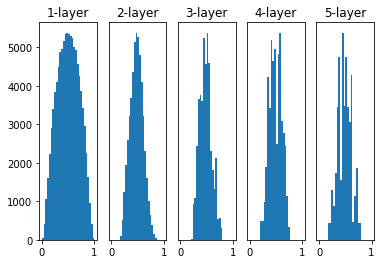
- 표준편차를 줄여 0.01로 테스트를 해보면 아래 그림과 같이 층이 깊어질 수록 출력값들이 중간 값인 0.5 부근에 몰리는 것을 확인할 수 있다.
- 이는 Zero Initialization 문제와 같이 모든 노드의 활성화 함수의 출력값이 비슷하면 노드를 여러 개로 구성하는 의미가 사라지게 된다.
Xavier Initialization
- 위의 Zero, Random Initialization으로 발생하는 문제를 해결하기 위해 고안된 초기화 방법으로, 고정된 표준편차를 사용하지 않고 각 층의 가중치를 그 층의 입력 노드 수와 출력 노드 수에 기반하여 조절된 분산을 가진 분포에서 무작위로 선택하여 초기화 한다.
- 이는 신경망의 깊이가 깊어져도 학습 초기 단계에서 안정적인 그래디언트를 유지하도록 한다.
- 주로 tanh, sigmoid 활성화 함수에 효과적 (대칭모양의 함수로, 가운데 부분은 직선에 가까워 선형 함수로 가정할 수 있기 때문)
- 이전 은닉층의 노드 개수가 개이고 현재 은닉층의 노드가 개일 때,
- 균등(Uniform)분포를 사용할 경우, 각 요소는 범위 내의 값으로 설정됨.
- 정규분포를 사용할 경우, 각 요소는 평균 0과 표준편차 의 분포로 설정됨.
He Initialization
- ReLU 함수의 경우 양수 구간에서 Xavier Initialization 초기화의 선형 가정이 유효하지만, 음수 구간에서는 입력 데이터가 0이 되면서 분산이 점점줄어 들어 출력이 0이 된다.
- 활성화 함수가 ReLU일 때 이러한 문제점을 개선한 방식이 He Initialization 이다.
- He Initialization은 ReLU를 사용했을 때 출력의 분산이 절반으로 줄어들기 때문에 가중치의 분산을 두배로 키운다.
- 이전 노드의 개수 에 대해서 균등(Uniform)분포를 사용하는 경우 범위 내의 값으로 설정되고,
- 정규분포를 사용하는 경우에는 를 표준편차로 하는 정규분포로 초기화함.
참고
- [DL] 가중치 초기화 (Weight Initialization)
- 가중치 초기화 (Weight Initialization)
- [모두를 위한 cs231n] Lecture 6. Weight Initialization
- [Deep learning] 가중치 초기화(weight initialization) (feat. Xavier, He,normal, uniform)
- [DL] 초기화와 정규화 - Xavier Initialization, He Initialization, batch normalization, weight decay, early stopping, data augmentation, bagging, Dropout — Sonstory