CNN based Models : ResNet 모델에 대한 정리
ResNet 개요
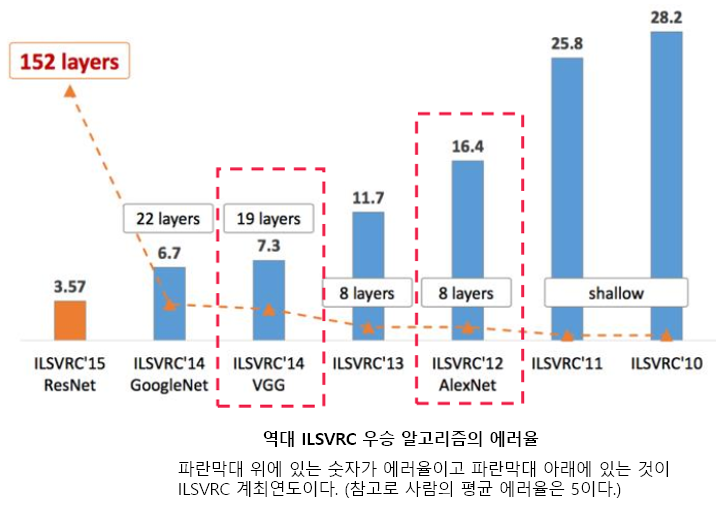
- ResNet은 마이크로소프트에서 개발한 아키텍처로, 2015년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)와 COCO에서 우승하며 처음으로 Human error를 능가하는 3.57%의 top5 error 를 보여줌
- 2014년의 GoogLeNet이 22개 층으로 구성된 것에 비해, 우승 모델인 ResNet-152는 152개 층을 갖는다
- 동일한 개념이지만 레이어 수가 다른 ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-110, ResNet-152, ResNet-164, ResNet-1202 등이 있다.
- 단순히 네트워크 깊이만 깊어지면 무조건 성능이 좋아지는지 확인하기 위해 저자들은 convolution layer들과 fully-connected layer들로 20층의 네트워크와 56층의 네트워크의 성능을 비교함
- 오히려 더 깊은 구조를 갖는 56층의 네트워크가 20층의 네트워크보다 더 나쁜 성능을 보임
- 깊은 layer에서 발생하는 gradient vanishing/exploding 문제
- 파라미터 수의 증가로 인한 학습의 어려움
- Paper : Deep Residual Learning for Image Recognition

Residual Learning
Identity Mapping (기저 이론)
- Identity mapping은 입력값과 출력값이 같은 매핑 (항등행렬의 항등 개념)
- 레이어가 매우 깊은 모델이라면 입력으로부터 차근차근 조금씩 입력값을 바꿔 나가는 것이 이상적일 것이라는 가정
- 그러기 위해서는 각 레이어의 계산과정에 각각의 입력값을 출력단에 그대로 전달(identity)하여, 학습 시 weight의 큰 변화를 막자(최소화 하자, residual(잔차)만 학습하자, 학습 난이도를 줄이자)
-
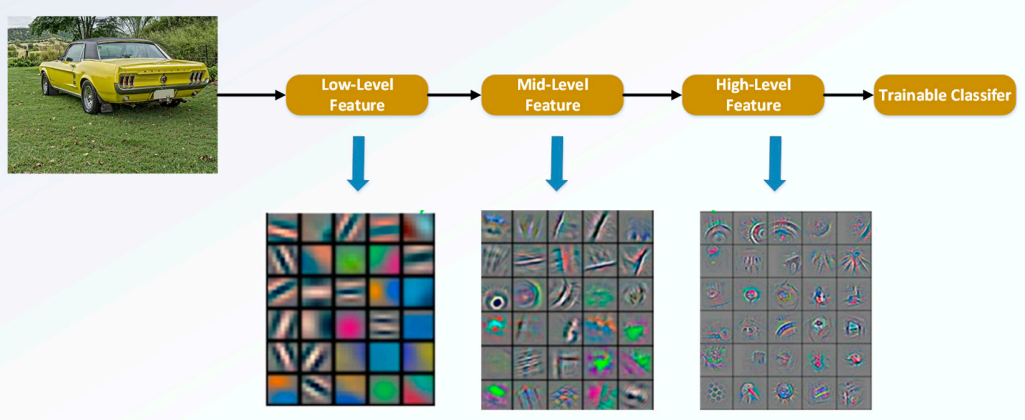
위 그림과 같이 CNN 구조에서는 입력부분에 가까운 하위 레이어에서는 매우 단순한 구조나 노이지한 패턴이 보이는 low-level feature가 학습이되고, 출력부분에 가까운 상위 레이어에서는 구조적인 부분이 학습되는 high-level feature가 학습됨
-
그런데 앞선 부분의 feature가 뒤쪽까지 영향이 직접적으로 전달되는 것이 아니라, 중간을 거쳐 전달되기 때문에 학습의 과정에서 크게크게 변한다 → skip-connection을 추가해주게 되면 이전으로부터 얼만큼 변하는지 나머지(residual)만 계산하는 문제로 바뀜. 즉, 현재 레이어의 출력값과 이전 스케일의 레이어 출력값을 더해 입력을 받기 때문에, 그 차이를 볼 수 있게 되는 것. 따라서 학습하는 과정에서 그 ‘조금’을 하면 되는 것이고, 더 빠르고 정확하게 학습이 된다는 장점이 생김
-
예를 들어, 잘 학습된 ResNet-50은 34→36 레이어 출력값 사이의 값의 변화가 그리 크지않을 것이다.
-
따라서, 는 입력값인 에 근사 할 것이다 ⇒
Residual Block
- ResNet 아이디어의 핵심으로, Residual(잔차)를 학습함 → Gradient가 깊은 위치까지 잘 도달할 수 있게 지름길을 만들어줌(skip-connection)
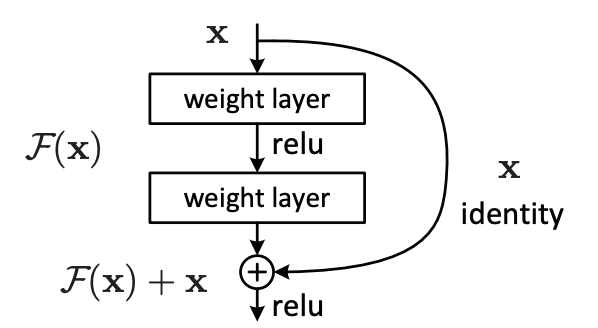
기존 방식
- 기존 방식은 입력 를 받고 direct로 가 출력됨 (는 Convolution과 Relu의 반복 연산)
- 를 타겟값인 로 매핑하는 함수를 찾는 것이 목적
- 즉 신경망은 학습을 하면서 의 값을 최소화하면서 가되는 함수를 찾음
- 이때 타겟값 는 입력값 를 통해 새롭게 생성하는 정보(기존 학습한 정보를 보존하지 않고 변형시켜 새롭게 생성됨)
Residual block
- Residual Learning 방식은 으로, 타겟값 에 기존 입력 정보인 값을 힌트로 줌
- 를 묶어 라 할 때, Identity Mapping (기저 이론)에 따라 가 되는 것을 목표로 학습됨
- 즉, 이 되도록 학습하며 각 레이어의 계산과정에 각각의 입력값을 출력단에 그대로 전달(identity)하여 학습 시 weight의 큰 변화를 막아 학습 난이도를 줄이며 gradients vanishing 문제에도 효과적임
- 이러한 입력값 의 정보를 몇 단계뒤의 출력에 알려주는 것을 skip-connection (shortcut) 이라함
- Resnet에서는 skip-connection이 포함된 2개 이상의 Conv Layer를 하나의 Block으로 묶어 이를 Residual Block이라 명명함
- 는 residual block 내 레이어 개수, 와 는 residual block의 입력과 출력일 때, 수식은 아래와 같음
- 이때 와 기존 정보 의 차원이 달라 단순 더하기 연산이 불가능한 경우, 차원을 맞춰 주기 위한 를 사용함 (linear projection)
Residual block 학습 (역전파)

- 위 그림은 resdiual block의 역전파 시 gradient의 전파 경로를 나타낸 그림으로, 파란색 선은 기존의 전파경로를 표현함
- 초록색 선은 skip-connection으로 생긴 지름길의 전파경로이며 loss로부터 gradient가 를 건너 뛰고 바로 으로 전달되는 모습을 볼 수 있음
- 이러한 역전파 시 지름길의 전파경로는 입력층과 가까운 층까지 gradient가 잘 전달될 수 있도록함
- 함수 를 skip-connection이 포함된 블럭에서 기존 경로로 계산되는 식이라고 하면 는 아래와 같이 표현할 수 있다
- Loss 함수에 대한 입력 가 미치는 영향(기울기)을 구하면 아래와 같다
- 에 대한 의 기울기를 구하면 아래와 같다
- 다시 위 식에 대입해보면 다음과 같이 정리됨
- residual block의 기울기 정리를 보면, 를 기준으로 좌항은 가중치 레이어를 지나며 gradient가 0으로 수렴할 수 있지만, 우항의 가 살아있으므로 gradient를 보장할 수 있다
- 가 되도록 학습 > 의 에 대한 미분 결과가 이므로 gradient 값이 항상 1 이상이다 > gradient vanishing 문제를 해결
- 가중치 을 업데이트하는 역전파 수식은 아래와 같음
- 를 체인룰로 표현하면 아래와 같다

- 위 식에서 좌항은 기존 gradient를 계산하는 식이고, 우항은 지름길(shortcut)로부터의 gradient를 계산하는 식임
- 좌항의 기존 gradient는 컨볼루션과 활성화함수의 연산을 거치며 기울기가 0에 수렴할 위험이 여전히 크다
- 하지만 지름길로부터의 gradient는 기존 gradient와 달리 곱해야 할 gradient 요소들의 개수가 줄어든 모습을 볼 수 있어 gradient 값을 유지하는데 도움을 줄 수 있다
- gradient가 최소 1이 보장되므로 0으로 수렴할 일이 없어 항상 모든 정보가 통과하며, 지속적인 residual learning이 가능하여 깊게 레이어를 쌓을 수 있음
- 결국 지름길로부터의 Gradient는 0이 되지 않고 살아남을 확률이 커져 네트워크의 깊이를 깊게 만들어주어도 gradient가 더 잘 전파되어 잘 학습할 수 있게 됨
ResNet Architecture
ResNet-34
- ResNet은 기본적으로 VGG-19의 구조를 뼈대로하며, 컨볼루션 층들을 추가해서 깊게 만든 후에 shortcut들을 추가 하였다
- 아래는 VGGNet과 비슷한 콘셉트로 만들었지만 Residual Learning 개념이 적용되지 않은 Plain 모델, 그리고 Residual Learning 개념을 적용한 모델의 Architecture를 표현한 그림
- 34-layer ResNet은 처음을 제외하고는 균일하게 3x3 사이즈 컨볼루션 필터를 사용하고, 특성맵의 사이즈가 반으로 줄어들 때, 특성맵의 뎁스를 2배로 높임
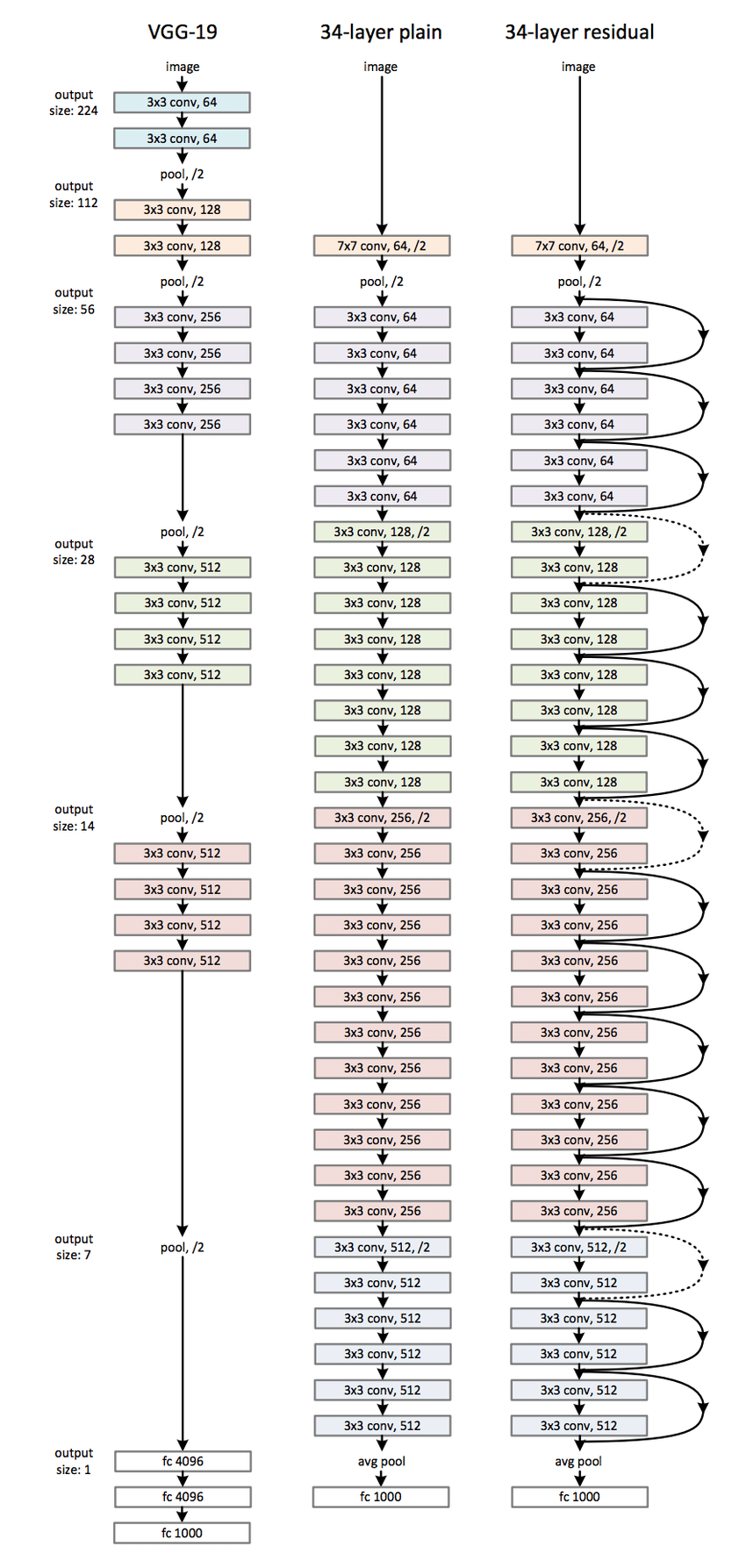
Residual Block 상세
1-convolution
- 모델은 아래와 같은 3x3필터 컨볼루션 작업의 반복으로 구성됨
- 입력에 Padding=1을 취해주고 3x3x64필터 64개를 Stride=1의 컨볼루션 연산을 통해 입력사이즈와 같은 (56x56x64) 출력이 나옴

- 위 연산을 하나의 Residual block으로 확장하면 아래와 같다

- 동일한 절차를 이어 아래와 같이 나타냄

2-convolution
- 두 번째 컨볼루션 구조에서는 처음으로 3x3x64필터 128개와 Padding=1, Stride=2를 통해 Depth를 늘림(Down Sampling)
- 28x28x128 출력이 나옴

-
이때 skip connection의 덧셈을 위해 인풋 피처맵(56x56x64)는 아래와 같이 처리하며, 이러한 처리 방식을 Projection Shortcut이라고함
-
1x1x64필터 128개를 컨볼루션하여 아웃풋 피처맵과 동일한 구조(28x28x128)로 만든 후 skip connection에 사용함

-
두 번째 종류의 컨볼루션의 최종은 아래와 같음


여러 층의 ReNet 구조
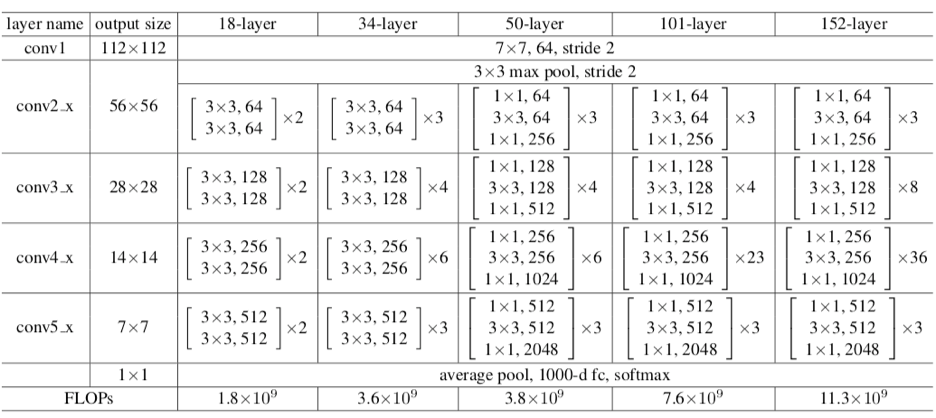
- 아래 표는 18층, 34층, 50층, 101층, 152층의 ResNet이 어떻게 구성되어 있는지 나타냄
- ReNet-50/101/152 구조에서는 Bottleneck구조가 사용됨
Bottleneck 구조
- Resnet-50/101/152 모델에서 연산을 줄이기 위해 사용되며 아래 그림 처럼 residual block이 1x1, 3x3, 1x1으로 구성된다. 이러한 모양이 병목처럼 보이기 때문에 Bottleneck 구조라 함
- block의 처음에 1x1 convolution은 Inception의 구조에서 살펴본 것 처럼 차원을 줄이기 위한 목적이며 이렇게 차원을 줄인 뒤 3x3 convolution 수행 후, 마지막 1x1 convolution은 다시 차원을 확대 시키는 역할을 함
- 결과적으로 3x3 convolution 2개를 곧바로 연결시킨 구조에 비해 연산량을 절감 시킴

- Bottleneck의 예시

ResNet V2
- 아래는 ResNet-V1 과 ResNet-V2의 기본 아키텍쳐를 보여줌

- ResNet-V1은 와 사이에 add 후 두번 째 ReLU 연산을 하지만, ResNet-V2는 마지막 ReLU를 제거하였고, conv 연산을 하기전에 입력에 BN 및 ReLU를 적용함
- 따라서 ResNet-V2는 마지막 ReLU를 제거하여 ID 매핑으로 만드는 데 중점을 두며, 출력 레이어에서 계산된 gradient 값은 변화 없이 쉽게 초기 레이어에 도달할 수 있게 함
ResNet 성능평가
Plain vs. ResNet
- Shortcut을 활용한 Residual Blcok이 효과가 있는지 평가하기 위해 18층 및 34층의 plain 네트워크와 ResNet의 성능을 비교함

- 왼쪽 그래프를 보면 plain 네트워크는 망이 깊어지면서 오히려 에러가 커졌음을 알 수 있다. 반면, 오른쪽 그래프의 ResNet은 망이 깊어지면서 에러도 역시 작아짐
- shortcut을 연결해서 잔차(residual)를 최소가 되게 학습한 효과가 있다는 것
ResNet 깊이에 따른 성능비교
- ResNet 은 깊이가 깊어짐에 따라 더 낮은 에러를 보였고, 1000개 이상의 layer가 쌓였을 때는 오버피팅이 일어났다고 함

Post-activation vs. Pre-activation 비교
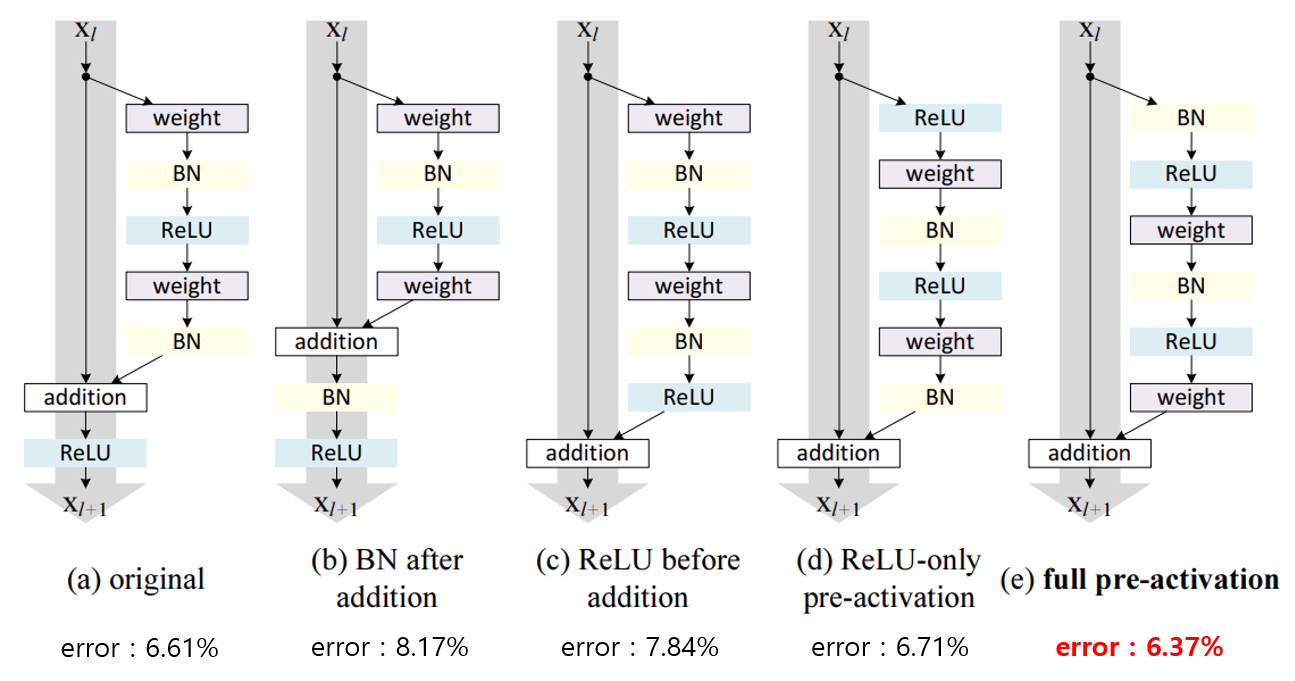
- 아래 그림은 activation 위치에 따라 변화하는 에러율을 나타내며, ResNet-V2로 가는 과정을 보여줌
- 최종적으로 (e)의 구조처럼 Batch Normalization과 ReLU 모두 weight앞에 위치한 full pre-activation 구조가 가장 좋은 성능을 보여줌
- 또한, (e) 구조는 Batch-Normalization을 통과해 정규화된 신호가 weight layer를 통과하기 때문에 상대적으로 overfitting이 덜 일어나서 일반화 성능이 올라가는 결과를 보여줌
참고
- K_05. Understanding of ResNet - Deep Learning Bible - 2. Classification - 한글
- ResNet의 이해
- CNN의 Bottleneck에 대한 이해
- 3) ResNet, ResNet의 확장(레이어 152개 이하) - 한땀한땀 딥러닝 컴퓨터 비전 백과사전
- (7) ResNet (Residual Connection)
- ResNet 논문 리뷰 : 지름길을 통해 Gradient Vanishing을 극복한 모델
- CNN 모델 탐구 (6-2) Identity Mapping in ResNet : 네이버 블로그
- Computistics - [Classification] ResNet
- Skip Connection and Explanation of ResNet | by Chau Tuan Kien | Medium