Fast R-CNN 개요
-
기존 R-CNN은 Region Proposal을 생성한 후, 각 영역을 CNN에 넣어 특징을 추출하고 SVM으로 분류했는데, 이 방식은 속도가 매우 느리고 학습/추론 과정이 비효율적임.
-
또한 3가지의 모델(AlexNet, linear SVM, Bounding box regressor)을 독립적으로 학습시켜, 연산을 공유하거나 가중치값을 update하는 것이 불가능.
-
이러한 문제를 개선하기 위해 Fast R-CNN은 한 번의 CNN feature extraction + RoI pooling + 멀티태스크 학습 방식을 도입하여 속도와 정확도를 동시에 높임.
-
여전히 Region Proposal(Selective Search)에 시간이 많이 걸리는 한계가 있으며 이를 해결하기 위해 Faster R-CNN은 RPN(Region Proposal Netwrok)을 도입해 속도를 대폭 개선함.
-
Paper : Fast R-CNN
Key-Points
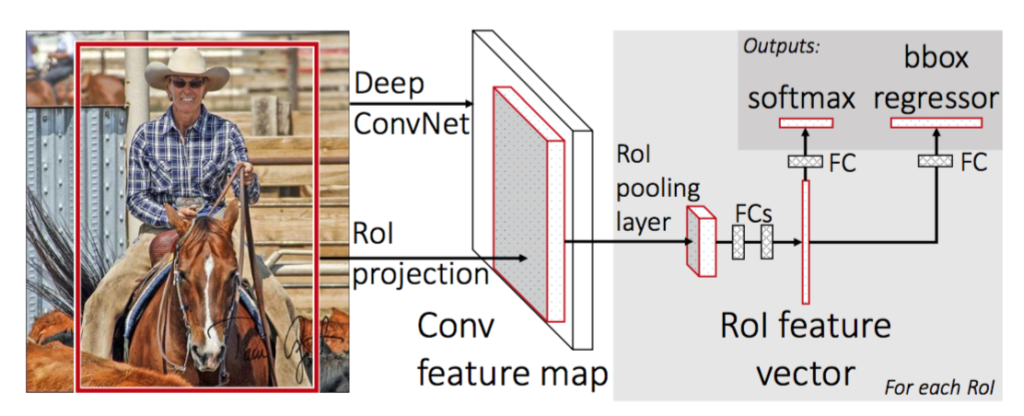
- R-CNN 모델은 2000장의 region proposals를 CNN 모델에 입력시켜 각각에 대하여 독립적으로 학습시키므로 많은 시간이 소요된 반면, Fast R-CNN은 단 1장의 이미지를 입력받아 RoI Pooling을 통해 고정된 크기의 feature를 fc layer에 전달함.
- 또한 Multi-task loss를 사용하여 모델을 개별적으로 학습시킬 필요 없이 한 번에 학습 시킴.
RoI Pooling
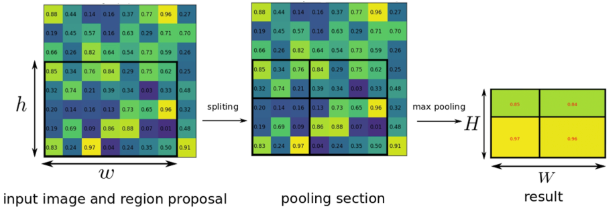
- RoI(Region of Interest) Pooling은 feature map에서 region proposals에 해당하는 관심 영역(Region of Interest)을 지정한 크기의 grid로 나눈 후 max pooling을 수행하는 방법.
- region proposal마다 CNN을 반복 적용하지 않고, 이미지를 한 번 CNN에 통과시켜 feature map을 생성.
- 이후 모든 region proposal은 이 feature map 위에서 처리 → 연산량 대폭 절감.
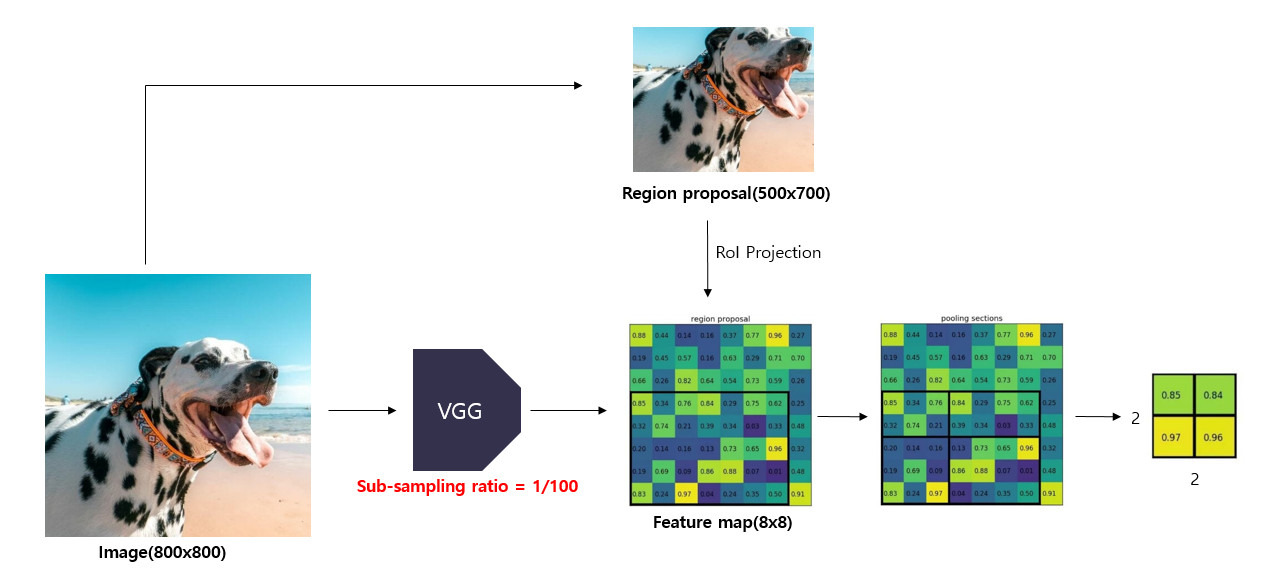
- 원본 이미지를 CNN 모델에 통과시켜 feature map을 얻고, selective search를 통해 여러개의 region proposal을 얻는다. (논문에서는 약 2000개의 region proposal을 생성함)
- feature map에서 원본 이미지에 비해 sub-sampling된 비율만큼의 region proposal 영역을 투영함.
- 투영된 영역을 미리 설정한 sub-window 크기()에 맞게 grid로 나누어줌.
- grid 영역에 대하여 max pooling을 수행하여 고정된 크기()의 feature map을 얻는다.
- 이렇게 추출된 feature map들은 region proposal의 개수 만큼 존재하고, 이후 FC layer의 입력이 된다.
Multi-task loss
- Fast R-CNN 모델에서는 feature vector를 multi-task loss를 사용하여 Classifier와 Bounding box regressior을 동시에 학습시킵니다.
- 이는 R-CNN과 달리, Fast R-CNN에서는 CNN과 RoI Pooling을 통해 추출된 동일 feature map이 Classifier와 Bounding box regressior에 공유되므로 end-to-end 학습이 가능하다.
- multi-task loss는 아래와 같다.
-
: 개의 class score (Softmax 출력 확률 벡터)
-
: Ground Truth class score (배경 클래스면 )
-
: 예측한 bounding box 좌표를 보정값 ()
-
: Ground Truth bounding box 좌표 (정규화된 값)
-
: Classification Loss
- Softmax cross-entropy :
- 예측 확률 에서 정답 클래스 의 확률을 크게 만들도록 학습
- Softmax cross-entropy :
-
: Localization Loss
- Smooth L1 loss :
- Smooth L1 loss :
-
: 배경 클래스일 경우 를 적용하지 않음
-
: 두 손실 항목의 비율 가중치 (논문에서는 1로 설정)
-
K개의 class를 분류한다고할 때, 배경을 포함한 (K+1)개의 class에 대하여 Classifier를 학습시켜줘야 한다.
Hierarchical Sampling
- Selective Search로 뽑은 약 2000개의 RoI는 이미지마다 존재하며 학습 시 모든 RoI를 한 번에 처리하기에는 연산 부담이 크고, RoI는 대부분 배경(Background)이므로 학습이 불균형해짐.
- Hierarchical Sampling은 Mini-Batch SGD 학습 시 한 서로 다른 N개의 이미지에서 R개의 region proposal을 sampling하여 Mini-Batch를 구성함.
- 논문에서는 N=2, R=128로 설정하여 총 256개의 RoI를 샘플링하고, 이때 각 이미지에서 25%는 ground truth와 IoU값이 0.5 이상인 sample (foreground)를 추출하고, 나머지 75%는 IoU 값이 0.1~0.5 사이의 sample을 추출하여 background()로 설정함.
Fast R-CNN 구조 및 학습
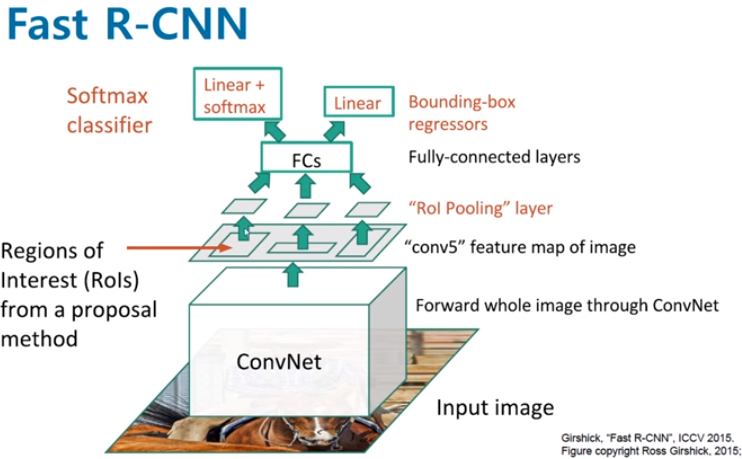
1) Initializing pre-trained network
- feature map을 추출하기 위해 VGG16 모델을 수정하여 사용한다.
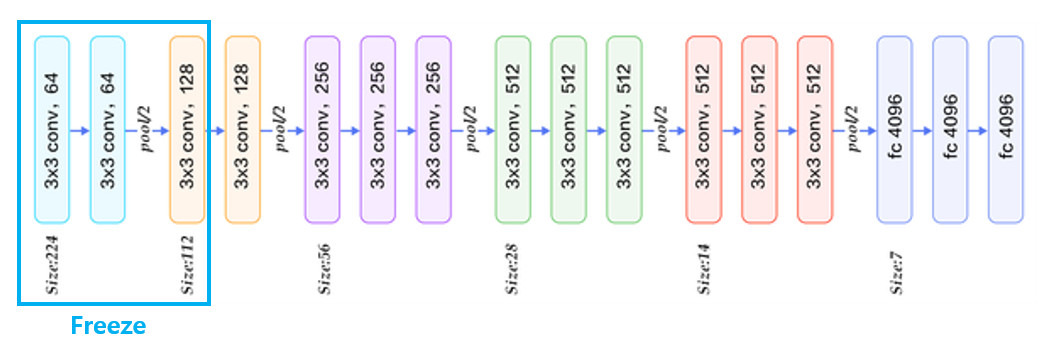
- VGG16 모델의 마지막 max pooling layer를 RoI pooling layer로 대체함. 이 때 RoI pooling을 통해 출력되는 feature map의 크기인 H, W는 후속 FC layer와 호환 가능하도록 7x7로 설정함. (7×7×512 = 25088)
- 네트워크의 마지막 FC layer를 2개의 FC layer로 대체함.
- Classifier : class와 배경을 포함한 개의 output을 가짐
- Bounding Box Regressor : 배경을 제외한 박스좌표 개의 output을 가짐
- conv layer3까지의 가중치값은 고정(freeze)시켜주고, 이후 layer(conv layer4~ fc layer3)까지의 가중치값이 학습될 수 있도록 fine tuning함.
- 네트워크가 원본 이미지와 selective search 알고리즘을 통해 추출된 region proposals 집합을 입력으로 받을 수 있도록 수정함.
2) Region proposal by Selective search
- 원본 이미지에 대하여 Selective search 알고리즘을 적용하여 미리 region proposal를 추출.
- 논문에서는 2000개의 region proposal을 추출함.
3) Feature extraction
- VGG16 모델에 224x224x3 크기의 원본 이미지를 입력하고, layer13까지의 feature map을 추출함.
- RoI pooling을 수행하기 전에 14x14x512의 feature map이 출력된다.
4) Max pooling by RoI pooling
- 출력된 feature map에 대하여 RoI projection을 진행한 후, RoI pooling을 수행함.
- 이 과정을 거쳐 고정된 7x7x512 크기의 feature map을 추출함.
5) Feature vector extraction by Fc layers
- region proposal별로 7x7x512(=25088)의 feature map을 flatten한 후 fc layer에 입력하여 fc layer를 통해 4096 크기의 feature vector를 얻는다.
6) Classifier / Bounding box regressor
- 4096 크기의 feature vector를 classifier와 bounding box regressor의 입력하여 각각 class score와 box 정보를 출력한다.
7) Multi-task loss
- Multi-task loss를 사용하여 하나의 loss를 반환하고, 역전파를 통해 classifier와 bounding box regressor를 한번에 학습시킨다.
정리
- Fast R-CNN 역시 inference 시에는 NMS 알고리즘을 적용하여 최적의 bounding box를 출력하게함. 또한 Truncated SVD를 적용하여 FC layer를 압축하여 inference 시간을 약 30% 단축할 수 있다고 제안함.
- Fast R-CNN 모델은 R-CNN 모델보다 학습 속도가 9배 이상 빠르며, detection 시, 이미지 한 장당 0.3초(region proposals 추출 시간 포함)이 소요됨.
- Overfeat의 핵심 아이디어가 FC layer가 고정된 크기의 feature vector를 입력받으니까 그냥 Conv layer로 대체해버리자 였다면, Fast R-CNN 논문에서는 새로운 pooling 방식을 도입하여 FC layer에 고정된 크기의 feature vector를 제공하는 방법을 제시했다.