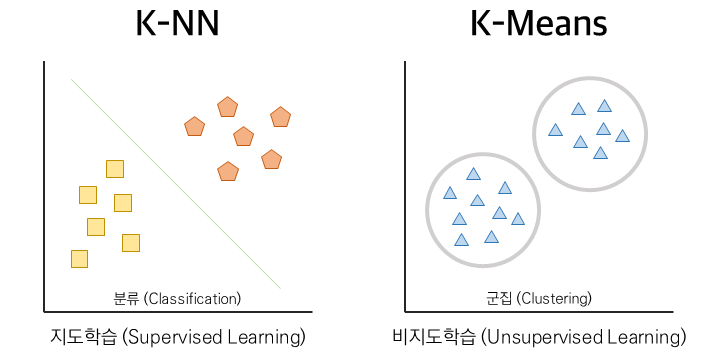
K-Means 개요
- K-Means 방법은 주어진 데이터를 K개의 군집(Cluster)로 군집화(Clustering) 하는 알고리즘으로, 정답 레이블이 없는 비지도 학습의 대표적인 방법이다.
- 각 군집(Cluster)은 중심점(cnetroid)을 기준으로 구성되며, 같은 군집 안의 데이터는 유사하게, 다른 군집과는 다르게 묶는 것을 목표로함.
K-Means 방법
- 주어진 데이터에 대해서 아래의 과정을 통해 K 개의 그룹으로 분류할 수 있다.
- 초기 데이터 설정 : 데이터 집합에서 무작위의 K 개의 포인트를 추출하고, 추출된 데이터는 각 클러스터의 중심점(centroid)으로 설정한다.
- 클러스터 할당 : 데이터 집합의 각 데이터에 대해 K 개의 클러스터 중심점과의 거리를 계산하고, 각 데이터를 가장 가까운 클러스터에 할당함.
- 중심점 갱신 : 2번 과정에서 할당된 클러스터 데이터를 이용해 각 클러스터별 중심점을 다시 계산하여 중심점을 업데이트한다.
- 수렴 조건 확인 및 반복 : 중심점이 더 이상 변하지 않거나, 변화가 충분히 작을 때 까지 2~3번 과정을 반복한다.
목적 함수
- K-Means는 클러스터 내 거리 제곱합을 최소화하려고 한다.
argminC1,…,Ckk=1∑Kx∈Ck∑∣∣x−μk∣∣2
- Ck : k 번째 클러스터
- μk : k 번째 클러스터의 중심점(centroid)
- x : 데이터 포인트
- 즉, 각 클러스터 내부의 오차 제곱합(SSE)을 최소화하는 중심과 할당을 찾는다.
K-Means 사용 시 고려해야할 점
- K : 클래스터 개수
- 데이터 군집화 목적에 맞게 설정하되 너무 작으면 과소분류, 너무 크면 과적합 위험.
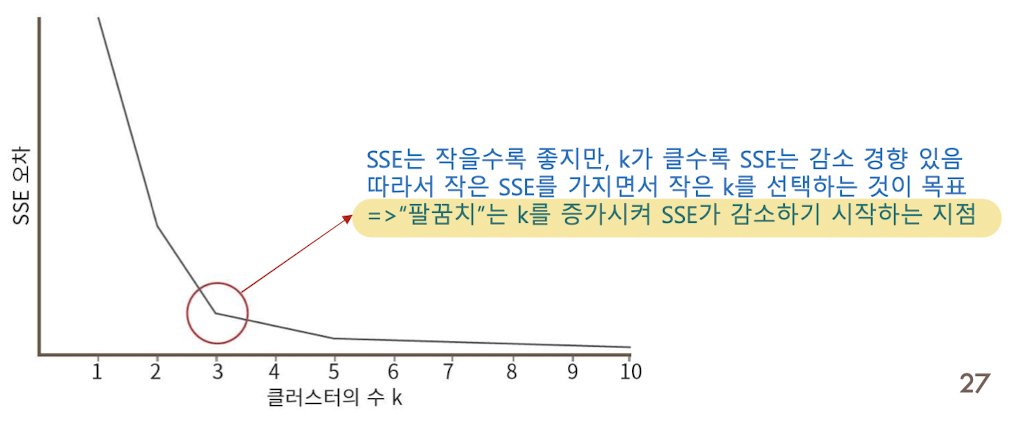
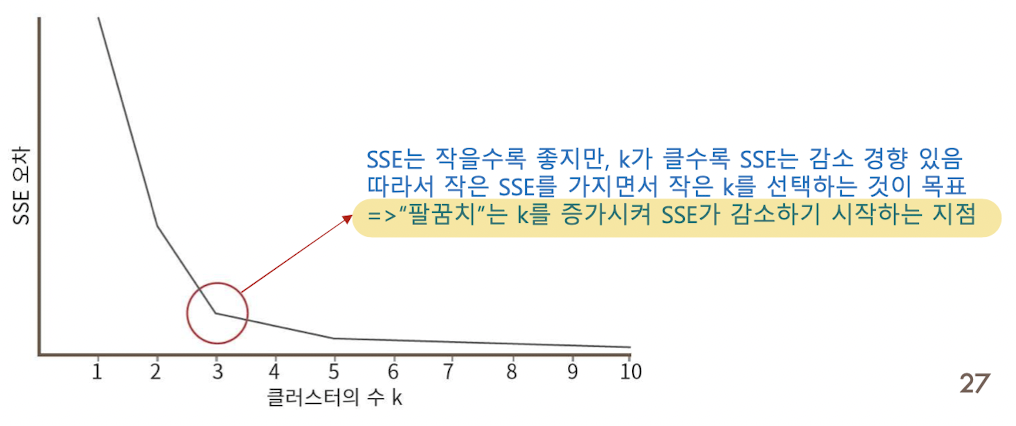
- 팔꿈치 방법 (elbow method):
- K 를 1부터 증가시키면서 K-means 클러스터링을 수행함.
- K 의 각 값에 대하여 SSE(sum of squared errors)의 값을 계산하고 아래와 같이 k에 대한 SSE의 꺾은선 차트를 그림.
K-Means 장단점
| 장점 | 단점 |
|---|
| 구현이 간단하고 빠름 | K(클러스터 수)를 사전에 지정해야 함 |
| 대용량 데이터에도 적용 가능 | 비구형 구조(복잡한 모양)는 잘 분리하지 못함 |
| 결과 해석이 직관적 | 이상치(Outlier)에 민감 |
| 거리 기반 클러스터링에 적합 | 초기값에 따라 결과가 달라질 수 있음 (지역 최적해) |
Python 예시 코드
Scikit-learn 을 이용한 K-Means 실습 코드
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 샘플 데이터 생성
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60)
# KMeans 모델 적용
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
# 결과 시각화
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red')
plt.title("K-Means Clustering 결과")
plt.show()
관련 개념
- K-Means++: 중심점 초기화를 더 똑똑하게 선택하여 성능 향상
- MiniBatchKMeans: 대용량 데이터에 적합한 확장형 KMeans
- Gaussian Mixture Model (GMM): 확률 기반 클러스터링으로, KMeans보다 더 유연함
참고