CNN based Models : AlexNet에 대한 정리
AlexNet 등장 배경
-
AlexNet은 2012년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 대회에서 압도적인 성능을 보여주며 컴퓨터 비전 분야에 지대한 영향을 미친 합성곱 신경망(Convolutional Neural Network, CNN) 모델이다.
-
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton 등이 개발한 AlexNet 논문은 딥러닝 분야에서 매우 중요한 역할을 했습니다. 이전까지는 컴퓨터 비전 문제에서 전통적인 기계학습 알고리즘이 주로 사용되었지만, AlexNet의 등장으로 딥러닝 기반 모델의 성능이 크게 향상되었다.
-
2012년 ILSVRC 대회에서는 단일 AlexNet 모델로도 18.2%의 낮은 오차율을 보였다. 결국 7개의 앙상블 AlexNet 모델로는 15.4%의 최고 성적을 거두며 우승을 차지했다. 이는 다음 순위 모델(26.2 %) 대비 10% 이상 성능이 향상한 결과였으며, 컴퓨터 비전 분야에 지각 변동을 일으킨 사건이었다.
-
Paper: ImageNet Classification with Deep Convolutional Neural Networks
+) LeNet (1998)
-
LeNet은 CNN을 처음 개발한 Yann LeCun의 연구팀이 1998년에 제시한 단순한 CNN 모델로서 합성곱 계층과 풀링 계층을 반복하고 마지막에 완전 연결 계층을 거치면서 결과를 출력함.
-
아래는 LeNet을 지칭하는 LeNet-5의 구조이다.
AlexNet 구조
입력 이미지

- AlexNet에 대한 입력은 256×256 크기의 RGB 이미지. 이것은 훈련 세트의 모든 이미지와 모든 테스트 이미지의 크기가 256×256이어야 함을 의미한다.
- 입력 영상이 grayscale이면 단일 채널을 복제하여 RGB 영상으로 변환하여 3채널 RGB 영상을 얻는다.
- AlexNet의 첫 번째 레이어에 공급하기 위해 256×256 이미지 내부에서 227×227 크기의 무작위 크롭이 생성된다. 논문에서는 네트워크 입력이 224×224라고 언급했지만 이는 실수이며 후에 227×227를 사용함.
- 데이터 증강을 위해 입력 이미지를 수평으로 반전시키거나 227×227 영역을 무작위로 추출하기도 한다.
네트워크 구조
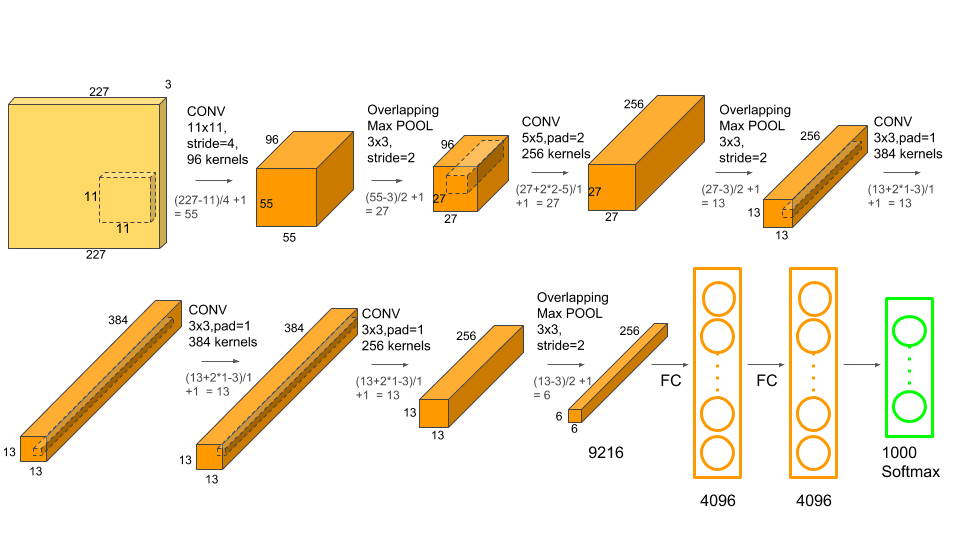
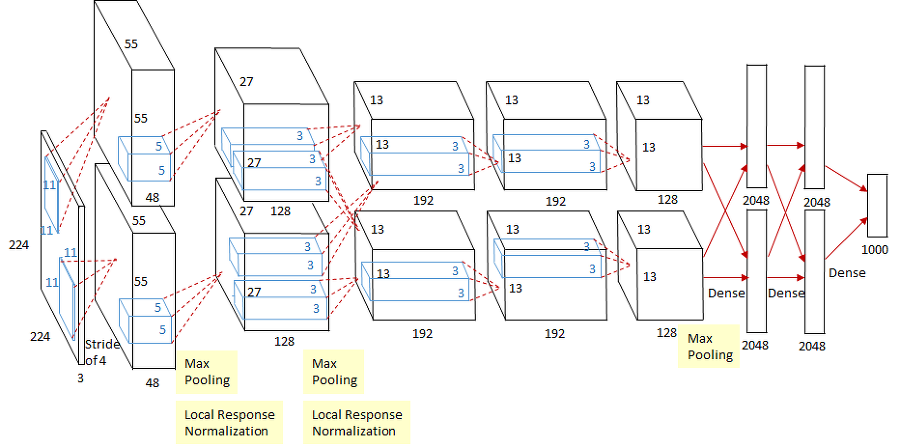
- AlexNet은 5개의 합성곱 계층(CNN) 과 3개의 완전연결 계층(FC) 으로 구성된 8계층 CNN 모델로서, 이전 CNN 모델에 비해 규모가 훨씬 크고 깊은 구조를 가지고 있다.
- CNN Layer 1
- 11x11x3 크기의 커널 48개를 2개 그룹 사용하여, 55x55x(48×2) 특징맵 출력 (stride=4, padding=0)
- 3×3 중첩 최대풀링 Overlapping Max Pooling 을 적용하여, 27x27x(48×2) 특징맵 출력 (stride=2)
- 지역 응답 정규화 Local Response Normalization 를 적용하고, 27x27x(48×2) 특징맵을 출력
- CNN Layer 2
- 5x5x48 크기의 커널 128개를 2개 그룹 사용하여, 27x27x(128×2) 특징맵 출력 (stride=1, padding=2)
- 3×3 중첩 최대풀링 적용하여, 13x13x128x2 특징맵 출력 (stride=2)
- 지역 응답 정규화를 적용하고, 13x13x128x2 특징맵 출력
- CNN Layer 3
- 3x3x256 크기의 커널 192개를 2개 그룹 사용하여, 13x13x192x2 특징맵 출력 (stride=1, padding=1)
- CNN Layer 4
- 3x3x192 크기의 커널 192개를 2개 그룹 사용하여, 13x13x192x2 특징맵 출력 (stride=1, padding=1)
- CNN Layer 5
- 3x3x192 크기의 커널 128개를 2개 그룹 사용하여, 13x13x128x2 특징맵 출력 (stride=1, padding=1)
- 3×3 중첩 최대풀링(stride=2)을 적용하여, 6x6x128x2 특징맵 출력
- Fully Connected Layer 6-8
- 5계층 합성곱 후 6계층, 7계층에서는 각각 4096개의 노드가 있습니다.
- 마지막 8계층에는 1000개의 노드가 있어 1000개 클래스 구분을 의미하는 확률값을 출력합니다.
- 파라미터 수와 계산 복잡도
- AlexNet에는 약 6천만 개의 학습 가능한 파라미터가 있습니다. 당시 GPU 환경에서 5~6일(!!)이 걸렸던 대규모 모델입니다.
AlexNet 핵심 기술
ReLU
-
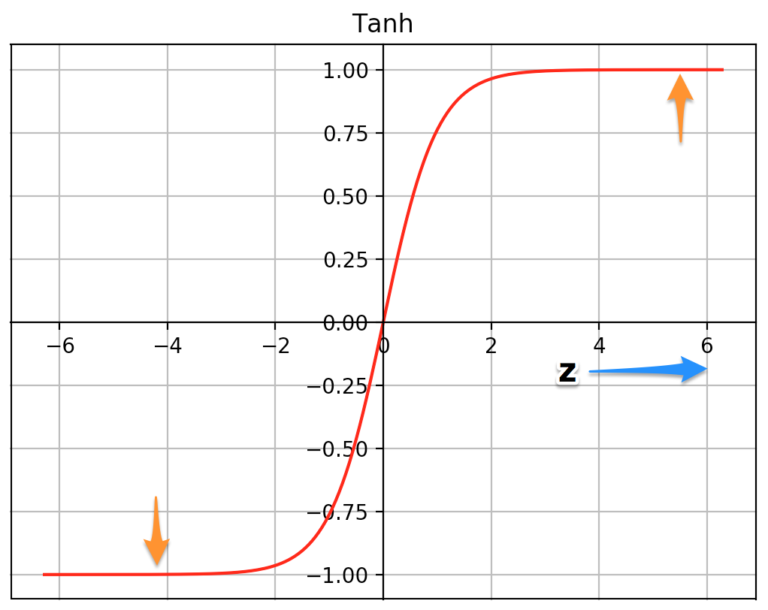
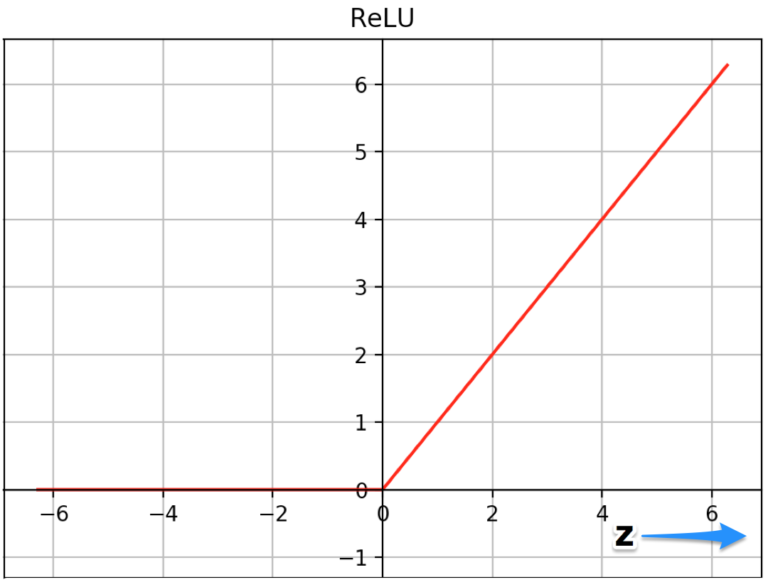
AlexNet에서는 기존의 tanh, sigmoid 활성화 함수 대신 ReLU 함수를 사용했다. ReLU는 음수 입력에 대해서는 0을 출력하고, 양수 입력에 대해서는 그 값 그대로를 출력한다.
-
아래 그림은 Tanh와 ReLU 함수 그래프 비교
-
ReLU를 사용하면 기존 활성화 함수보다 6배 더 빨리 수렴할 수 있었다. 이는 기존 함수들이 포화 영역에서 미분값이 0에 가까워져 학습이 느려지는 문제를 해결해주기 때문.
-
tanh 함수는 z의 매우 높거나 매우 낮은 값에서 분포되며 이 영역에서 함수의 기울기는 0에 매우 가깝다. 이것은 경사하강법을 늦출 수 있다. 반면에 ReLU 함수의 기울기는 z의 더 높은 양수 값에 대해 0에 가깝지 않고 이렇게 하면 최적화가 더 빨리 수렴되는 데 도움이 된다. z의 음수 값의 경우 기울기는 여전히 0이지만 신경망의 대부분의 뉴런은 일반적으로 양수 값을 갖게 된다. 같은 이유로 시그모이드 함수보다 우위에 있다.
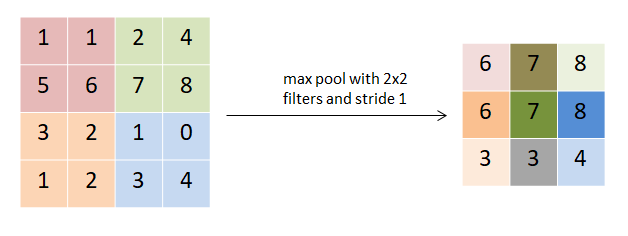
Overlapping Max Pooling
- Max Pooling 레이어는 일반적으로 깊이를 동일하게 유지하면서 텐서의 너비와 높이를 다운샘플링하는 데 사용됨
- 기존 CNN에서는 Pooling을 진행할 때, pooling unit 들이 겹치지 않게 연산이 되지만, AlexNet에서는 인접한 값들을 겹쳐서 연상을 수행하여 에러율을 감소시켰다고함 (kernel=3x3, stride=2 사용)

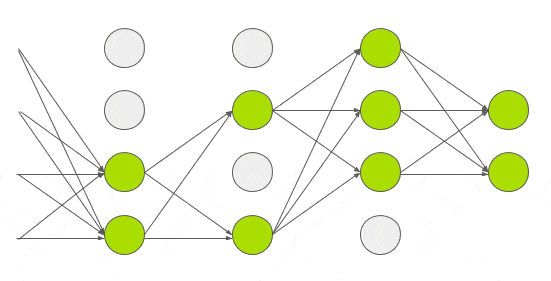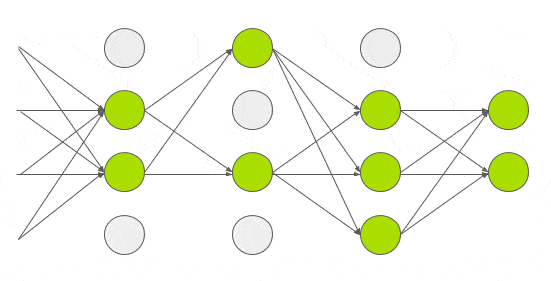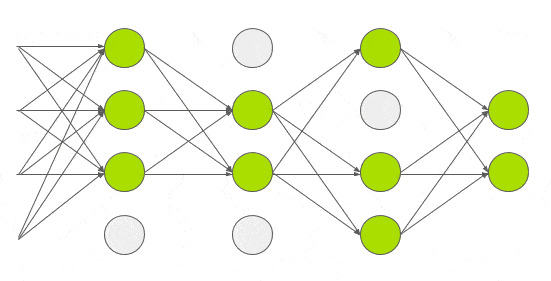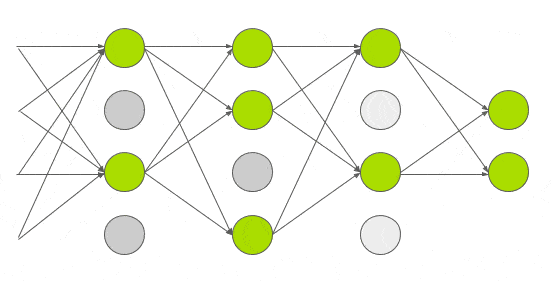
Dropout
- Dropout은 신경망의 과적합을 방지하기 위한 regularization 기술
- 각 iteration 마다 은닉층의 일부 노드를 무작위로 꺼서 과적합을 방지하며 AlexNet에서는 Fully Connected Layer에 0.5 확률의 dropout을 적용함
- AlexNet에서는 1번째와 2번째 Fully connected 레이어에 Dropout을 적용시켜 좋은 효과를 보았지만, 최종적으로 구하고 싶은 해에 수렴하기 까지는 2배 넘는 iteration 이 소모되었다고 한다
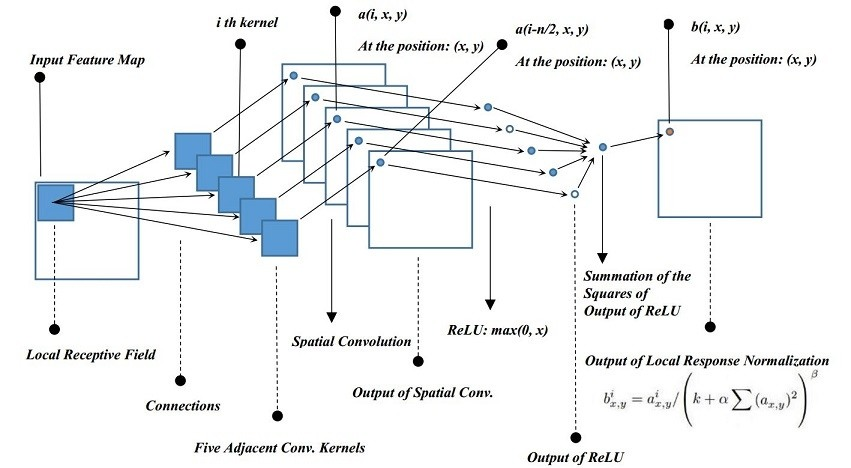
Local Response Normalization
- 현재는 Batch Normalization의 등장으로 잘 사용하지 않는 normalization 기법이지만, 당시에는 ReLU의 결과값이 너무 커져서 주변 뉴런에 영향을 주는 것을 방지하기 위해 normalization 기법이 필요했다. CNN 특성상 현재 픽셀에 대한 결과를 계산하기 위해 이웃한 픽셀도 참고하기 때문에 영향을 주게 되는 것이다.
- 지역 응답 정규화 과정은 모든 레이어에서 사용된 것은 아니고 특정 레이어에서만 사용되었으며, ReLU를 거치고 난 결괏값에 사용하였다. 이 정규화 방법을 통해 Top-1 에러율은 1.4%, Top-5 에러율은 1.2% 감소시킬 수 있다고 밝혔다.
Data Augmentation
- 과적합을 방지하기 위한 가장 쉽고 좋은 방법은 데이터의 라벨이 변형되지 않는 선에서 데이터를 임의로 추가하여 크게 하는 것이다. 따라서 저자들은 몇 가지 데이터 증강 방식을 선택했으며 특히 그 연산량이 적어서 따로 저장공간에 저장할 필요 없이 연산할 때마다 바로바로 처리할 수 있다고 한다.
- 이미지 평행 이동 : 입력 이미지에서 무작위로 227×227 영역을 잘라내어 데이터 수를 1024배 증가시킴.
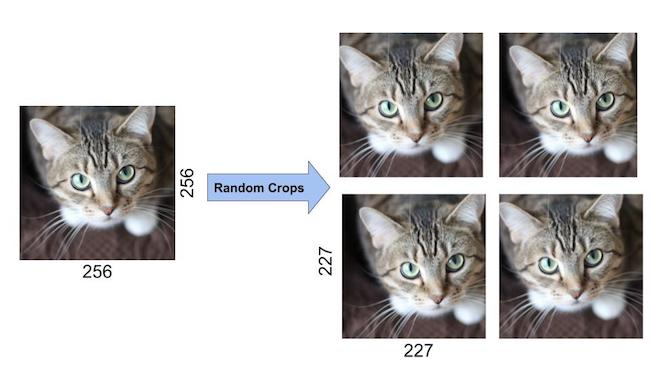
- 수평반전: 이미지를 수평으로 반전시켜 데이터 수를 2배로 늘림

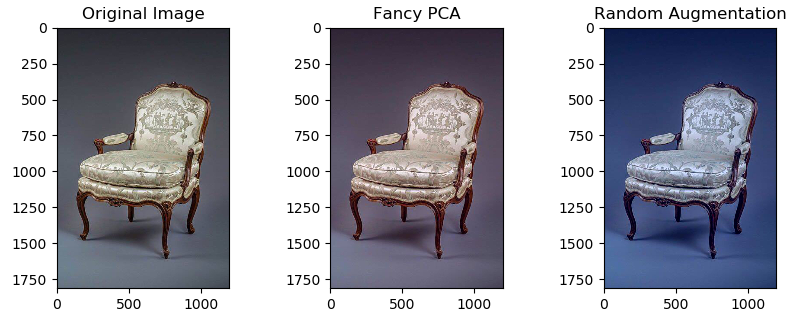
- 조명변환: 주성분분석(PCA)를 진행하고 평균(0), 표준편차(0.1)을 갖는 가우시안 분포에서 랜덤 변수를 추출한 후, 원래의 픽셀 값에 곱해주어 색상의 변형을 주는 방법이다. 이방식을 사용하게 되면 원래의 라벨을 해치지 않으면서 색상의 변형을 일으키는 것이 가능함
Multi GPUs
- 저자들이 학습에서 사용한 GPU는 GTX 580 GPU로 3GB의 메모리를 가지고 있는 장비이다. 학습 데이터셋으로 주어지는 120만장의 이미지는 모델을 학습시키기에 충분한 양이었지만, 그 개수와 크기는 GPU가 감당할 수가 없었다. 따라서 저자들은 2개의 GPU를 병렬적으로 사용하여 문제를 해결했다.
- 다만, 딥러닝의 특정 레이어에서만 2개의 GPU가 서로 데이터를 교환할 수 있게 만들고 나머지 레이어에서는 같은 GPU로부터 연산을 이어받을 수 있게 만들었다. 각각의 GPU는 커널을 절반으로 나누어서 연산을 처리하게 하여 하나에 가해지는 부담을 줄였다. 이 과정은 아래 AlexNet의 구조를 도식화한 부분에서 묘사되어있다.