CNN based Models : VGGNet에 대한 정리
VGGNet 개요
- VGGNet은 OxFord대학교의 Visual Geometry Group(VGG) 이 개발한 CNN 기반 Network
- 2014년 ILSVRC에서 2위에 그쳤지만 이해하기 쉬운 간단한 구조로 되어있고 변형이 용이하기 때문에 같은 대회에서 1위를 차지한 GoogleNet보다 더 많이 활용되고 있다
- CNN Network의 성능을 향상시키는 가장 기본적인 방법은 망의 깊이를 늘리는 것 으로, VGGNet은 이러한 망 깊이(depth)가 따른 네트워크의 성능변화를 확인하기 위해 개발된 네트워크
- VGGNet은 동일한 컨셉의 깊이가 다른 6가지 구조에 대해 성능을 비교했다 (3x3 커널 고정 조건)
Paper: Very Deep Convolutional Networks For Large-Scale Image Recognition
VGGNet 구조
Factoring Convolution
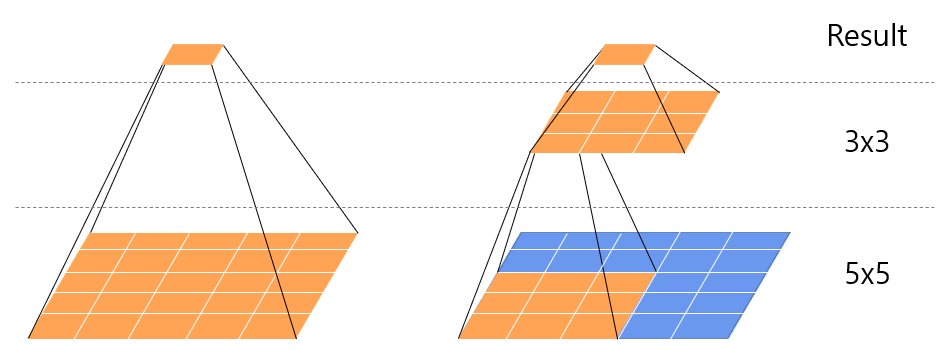
- 위 그림과 같이 kernel 사이즈가 5x5인 convolution은 2개의 3x3 convolution으로 분해(Factoring)할 수 있다
- 즉, 3x3 Conv layer를 중첩하면 5x5 Conv layer를 만들 수 있으며, 더 나아가 7x7, 9x9와 같이 큰 receptive field를 갖는 Conv layer를 3x3 Conv layer의 중첩으로 만들 수 있음
- 논문에서는 큰 사이즈의 필터 대신 3x3 사이즈의 필터를 사용하는 것이 두 가지 장점이 있다고 설명하는데,
- 첫 번째 장점은 비선형성(non-linearity)가 더 증가하여 더 좋은 차별성(구별력)을 가진 feature를 뽑아낼 수 있다고 함. 즉, 5x5 사이즈 필터 대신 3x3 사이즈 필터 두개를 사용하면 같은 영역을 볼 수 있는 동시에 더 좋은 feature를 추출하여 성능이 증가함
- 두 번째는 사용하는 파라미터의 수가 줄어들고, 학습 속도가 빨라지는 것. 입출력 채널 수가 같다고 할 때 5x5 Conv layer와 두 개의 3x3 Conv layer의 파라미터 수를 계산하면 아래와 같다. kernel size 5 : kernel size 3 :
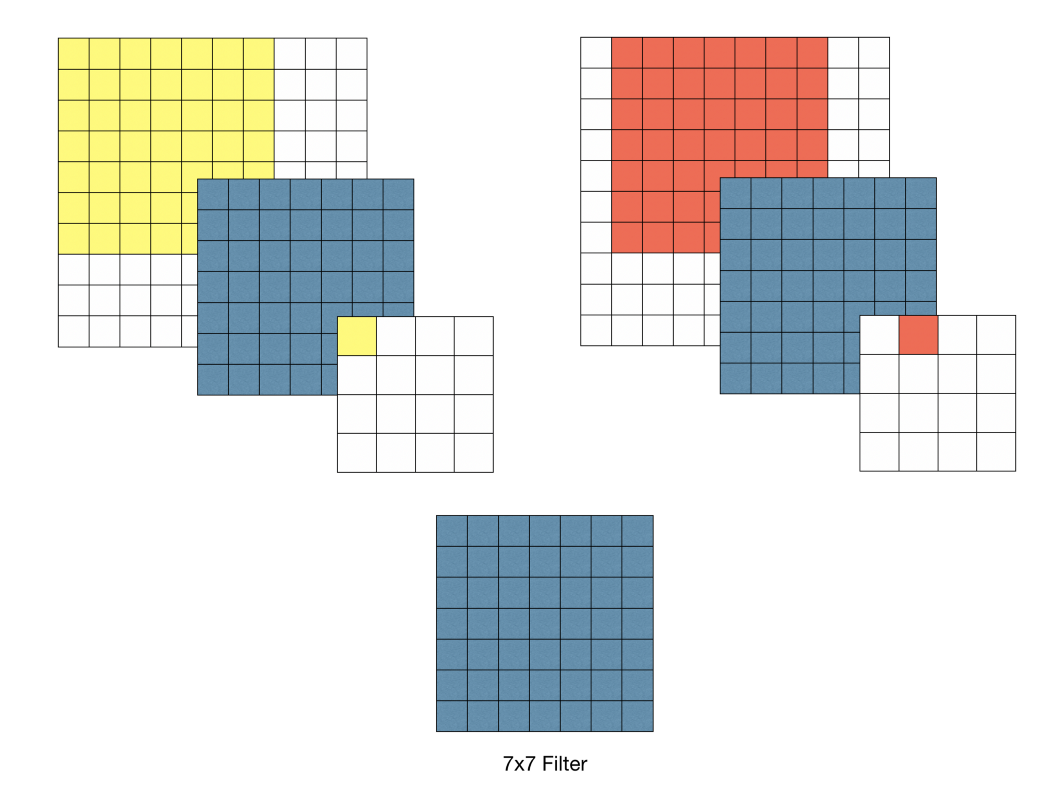 7x7 필터의 예시로, 7x7 = 49개의 파라미터 생성 | 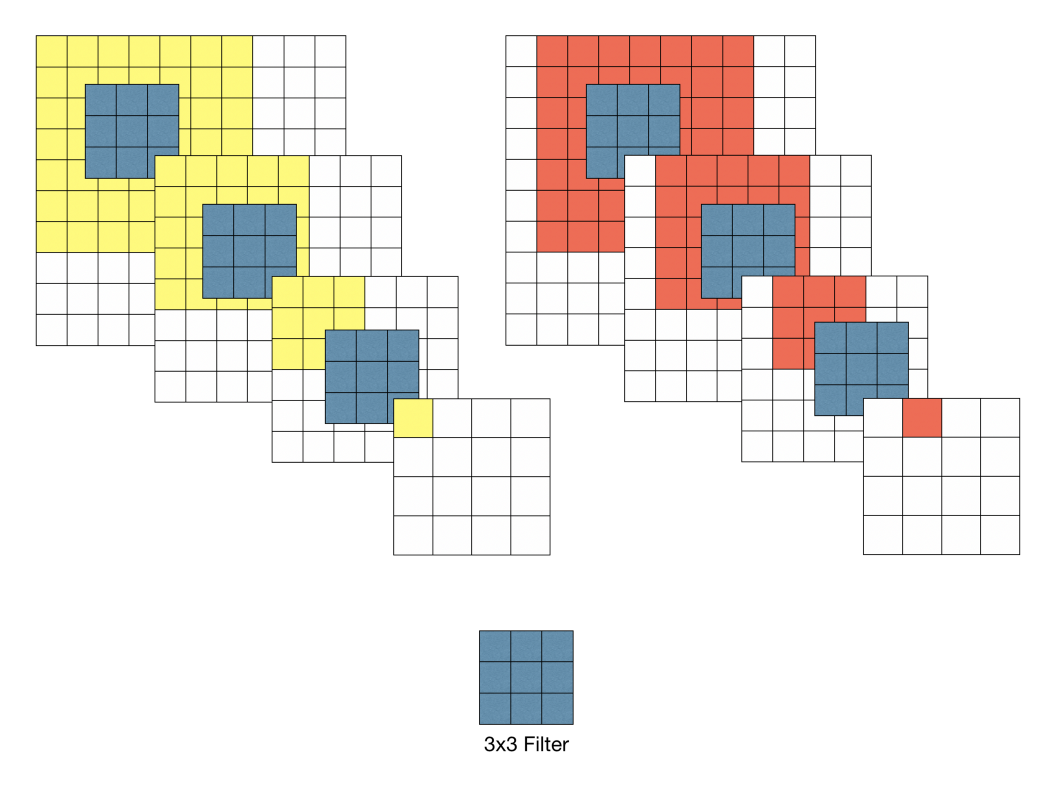 3x3 필터의 예시로, 3x3x3 = 27개의 파라미터 생성 |
|---|
네트워크 기본 구조
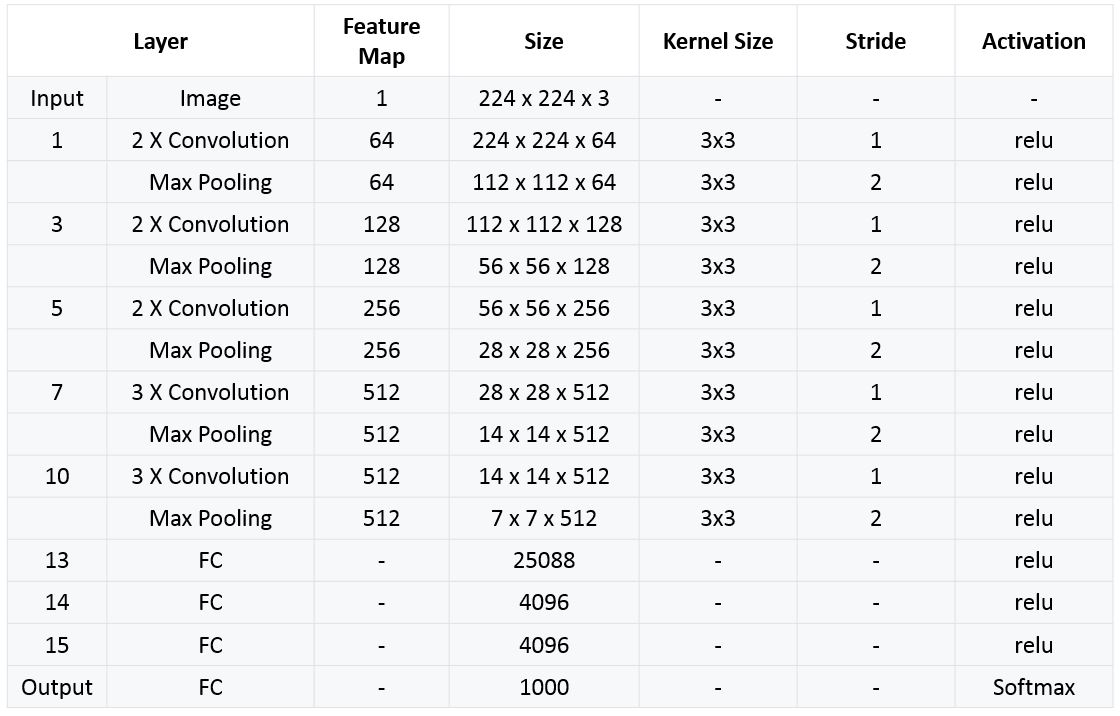
- VGGNet의 기본 구조는 Conv layer뒤에 max-pooling으로 해상도를 줄여가는 가장 기본적인 구조.
- 기존 CNN Network들 처럼 FC layer 3개를 뒤에 연결한 뒤 soft-max layer를 거쳐 각 클래스의 확률값을 계산함.
- Convolutional layer는 stride는 1에 padding 1을 주어 원 해상도가 유지되도록 만들었고, Conv layer 뒤에 2x2 window size에 stride 2를 갖는 max-pooling을 통해 해상도를 점차 줄여감.
- 채널 수는 64채널부터 시작하여 max-pooling으로 해상도를 줄일 때 마다 2배씩 늘려나갑니다.
- Fully-Connected layer의 경우 총 3개의 layer로 구성. 첫 번째와 두 번째 layer는 4,096개의 채널을 갖고 마지막 layer는 1,000개(ImageNet Dataset의 class 개수) 채널을 갖는다.
VGG-16
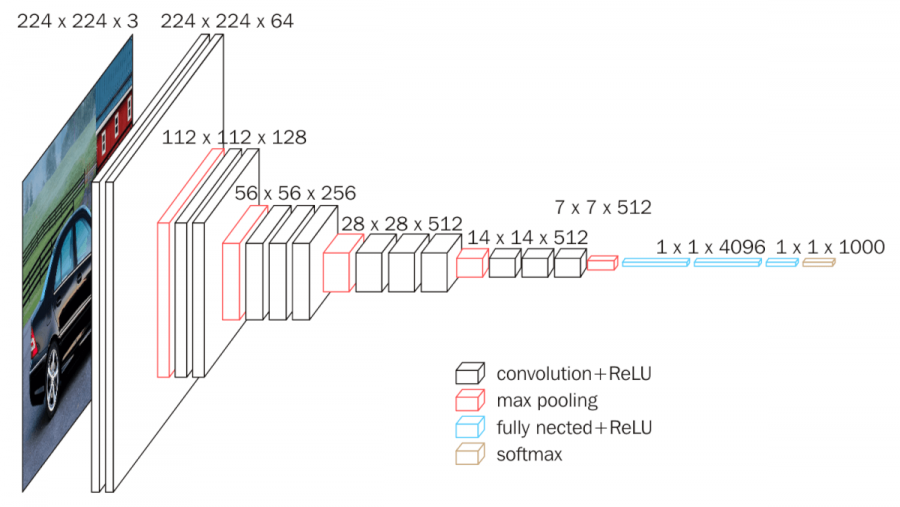
- VGG-16은 Conv 층 13개, FC 층 3개로 구성됨
- 컨볼루션 신경망에 대한 입력은 고정 크기 224 × 224 RGB 이미지이며 각 픽셀에서 훈련 데이터 세트에서 계산된 평균 RGB 값을 빼어 전처리함
- 이후 데이터는 특성 추출 과정을 거친다. 입력 데이터는 3×3 크기의 작은 필터를 여러 개 쌓아올린 컨볼루션 층들을 지나며, 필터 개수는 64 → 128 → 256 → 512로 점진적으로 증가합니다. 일부 층 다음에는 2×2 크기의 Max Pooling이 적용되어 데이터의 공간 해상도를 줄임.
- 모든 은닉층은 ReLU 활성화 함수를 사용함
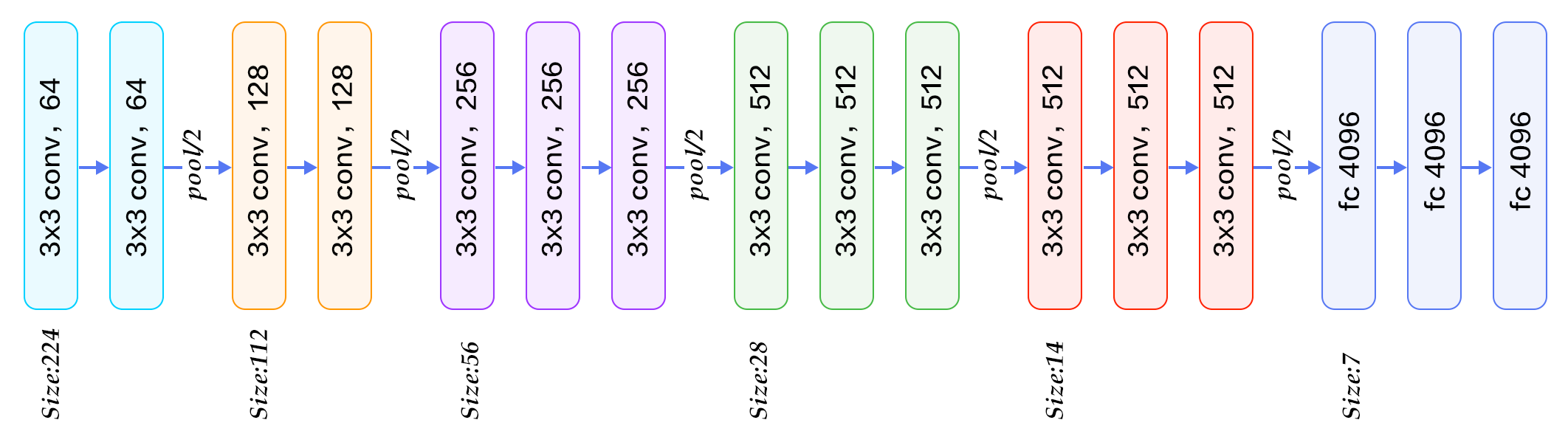
VGG-19
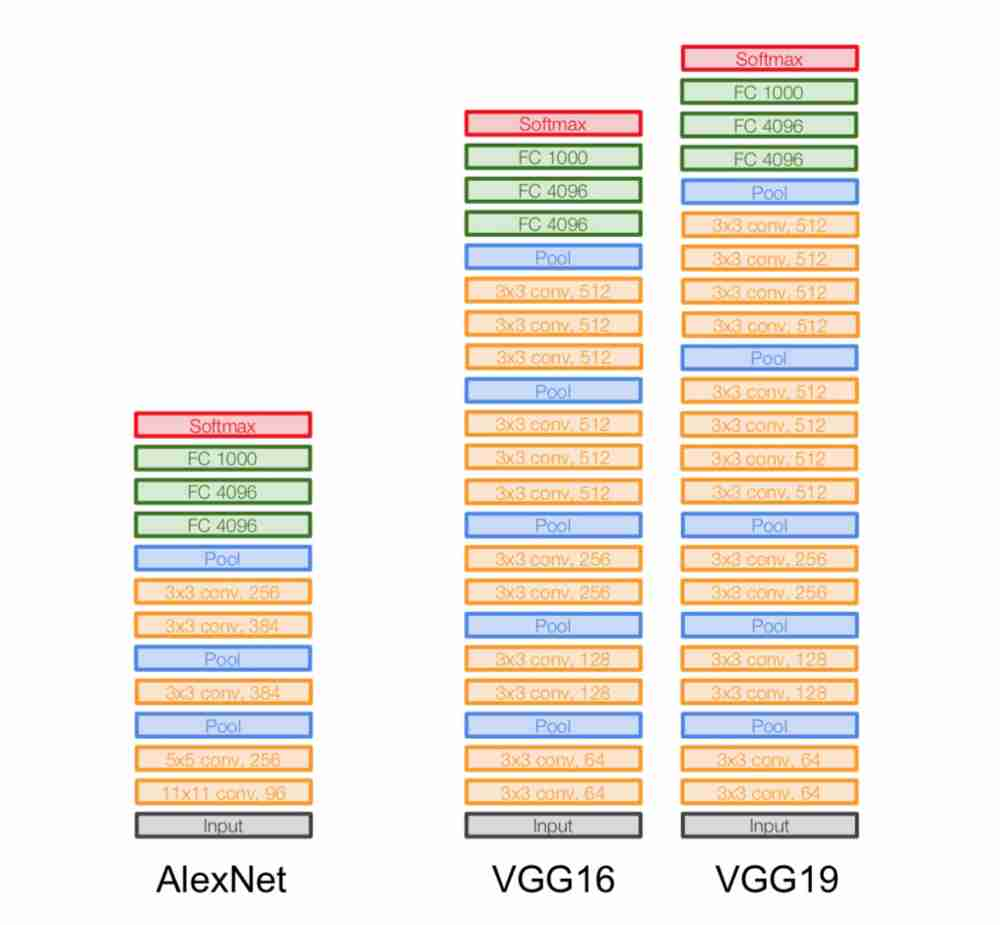
- VGG-19 구조는 단순히 VGG-16에서 Conv 레이어 3개가 추가된 구조
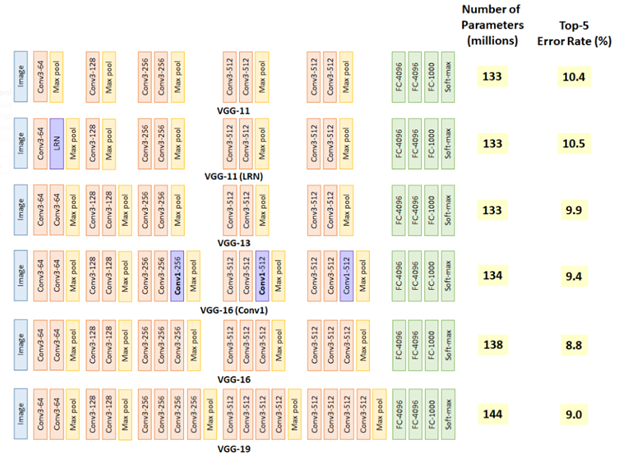
- VGGNet 은 여러 구조에 따른 6개의 모델을 제시함
VGGNet 학습 및 평가
VGGNet은 설계한 6개 구조에 대해 학습/평가 이미지의 scale과 같은 요소를 변화해 가며 성능이 어떻게 변화되는지 확인함
학습
- VGGNet또한 AlexNet과 같이 Overfitting에 빠지지 않게 하기위해 Data augmentation 기법을(특히 scale jittering) 활용함.
- 학습시에는 이미지의 짧은 변의 크기를 지정된 스케일로 리사이즈한 뒤 무작위로 224x224 영역을 1장 crop합니다. crop한 이미지는 AlexNet과 같이 수평반전과 RGB컬러성분 변경 과정을 거친다.
- Single-scale 학습에서는 256, 384 두개의 크기를 사용하며, 256을 먼저학습한 다음 384를 학습함
- Multi-scale 학습에서는 스케일을 [, ] 사이 값 중 랜덤으로 선정함. VGGNet은 256~512 사이 값 중 무작위로 선정된 스케일에 대해 학습함
- 학습 시 가중치들의 초기화는 가장 간단한 구조인 A구조에 대해 랜덤초기화 후 학습을 진행하고, 나머지 모델들은 앞선 구조의 가중치를 기본값으로 하되, 새롭게 추가된 레이어의 가중치는 랜덤 초기화함
평가
- VGGNet에서 평가할 땐 크게 세 가지 특징을 가진다.
- 첫 번째는 AlexNet, GoogLeNet 등 다른 CNN Network들과 마찬가지로 여러 스케일에 대해 평가한 결과를 합침으로써 성능을 높임. VGGNet의 경우 먼저 training scale S와 유사하게 test scale을 Q로 지정하여, 평가 할 이미지의 짧은 변을 Q로 변환한 이미지를 네트워크에 입력하며, 결과로 나온 각각의 class의 확률값의 평균값을 활용해 최종 결과를 도출함.
- 두 번째는 네트워크 제일 뒤에 붙는 FC layer를 Conv layer로 변환하여 fully-convolutional network로 만든다. 첫 번째 FC layer를 7x7 Conv layer로 바꾸고, 뒤의 두 FC layer는 1x1 Conv layer로 바꾼다. 이러한 fully-convolutional network로 변환함으로 입력 이미지 크기에 상관없이 네트워크를 동작시킬 수 있게 된다. 즉, VGGNet Network에 Q로 크기를 바꾼 평가 이미지를 입력할 때 crop없이 전체 이미지 입력할 수 있게된다.
- 마지막으로 이미지를 여러 스케일에서 평가할 때 multi-crop방식과 dense evaluation방식을 사용한다. Dense evaluation은 crop 이미지마다 네트워크에 입력하는것과는 달리 큰 이미지를 네트워크에 한번 입력한 다음 sliding window를 적용하는 것과 같이 일정한 간격으로 결과를 도출할 수 있는 방법이다. 이는 연산 관점에서 매우 효율적이지만, grid크기에 문제로 인해 성능이 나빠질 수 있기 때문에 실제로는 multi-crop을 상호 보완적으로 사용하였다고 함.
결과
VGGNet은 ILSVRC-2012 dataset의 validation set을 활용해 평가함
1) Single-scale
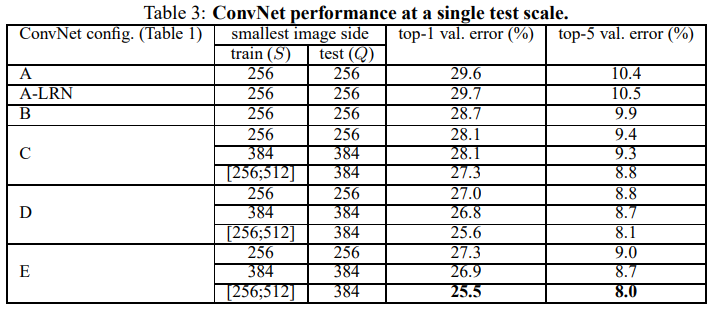
- 위 표는 평가용 이미지의 scale인 Q를 하나의 값으로 고정한 single-scale 평가 결과
- A와 A-LRN의 결과를 비교했을 때, LRN(Local Response Normalisation)을 적용한 결과가 미미하게 성능이 떨어짐
- 논문 저자들은 이 결과로부터 LRN이 유용하지 않다고 판단했으며, B~E 구조에서는 사용하지 않았다

- 학습/평가의 scale이 256인 결과만 봤을 때, 망의 깊이가 깊어질수록 error가 낮아지는 것을 볼 수 있다. 따라서 depth가 증가할 수록 성능이 좋아지지만 D와 E구조로 부터 19개 layer를 넘어가면 성능향상이 수렴하는 것을 볼 수 있습니다. 하지만 논문에서는 더 큰 데이터셋에서는 성능향상이 있을 수 있다고 언급함.

- B와 C를 보면 1x1 Conv layer를 활용해 비선형성을 높인 경우 성능이 향상되며, C와 D에서 1x1 Conv layer보다 3x3 Conv layer를 썼을 때 성능이 더 좋음을 확인할 수 있다.
- 이 결과로부터 1x1 Conv layer를 활용해 비선형성을 높이는 것이 성능향상에 도움이 되지만, 1x1보다 3x3 사이즈에서 성능이 더 좋은것으로 보아 주변 위치의 공간적 정보를 활용하는 것이 더 중요함을 알 수 있다.
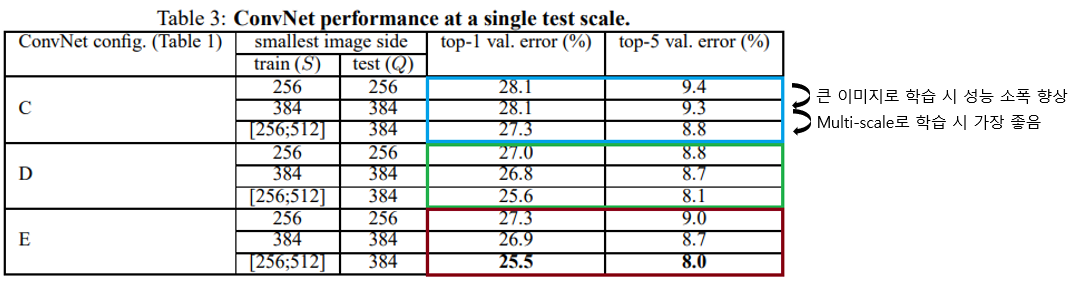
-
학습 시 scale jittering에 따른 성능변화를 보면 더 큰 S를 사용하는 편이 성능이 약간 좋으며, S를 하나의 고정 값으로 사용하는 single-scale 보다 multi-scale(256~512)을 사용하는 편이 더 좋은 성능이 나왔다. 이 결과로부터 학습할 때 scale jittering을 사용하는 것이 도움되는것을 알 수 있다.
-
B구조에서 3x3 Conv layer 두 개가 짝을 이루는것을 볼 수 있는데, 이것을 하나의 5x5 Conv layer로 바꾼뒤 성능을 확인했다. 그 결과 3x3 크기의 필터를 사용하면 top-1 error가 7%나 낮아짐을 볼 수 있었고, 작은 필터를 중첩해서 사용하는 것이 큰 필터 하나를 사용하는 것보다 더 좋음을 확인했다고 한다.
2) Multi-scale
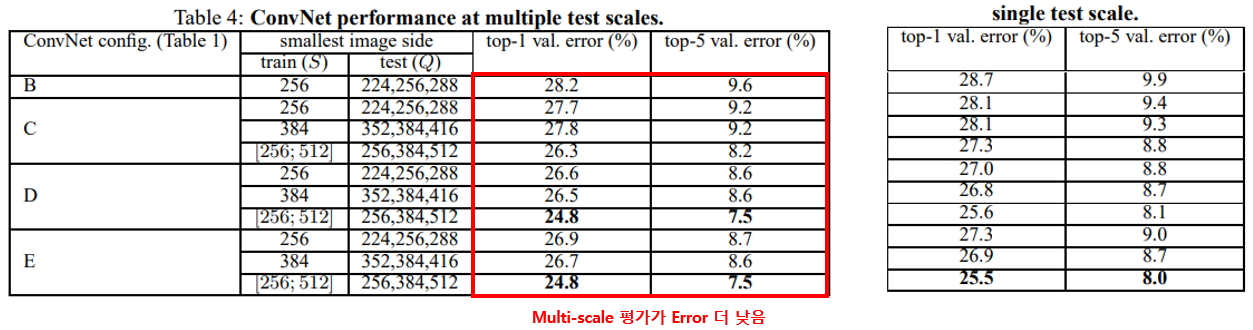
- single-scale 또는 multi-scale로 학습된 모델의 weight에 대해 3개 scale의 Q로 테스트했을 때 성능변화를 확인함
- 평가 시 multi-scale로 평가한 경우가 single scale로 평가한 것 보다 성능이 좋음
3) Multi-crop
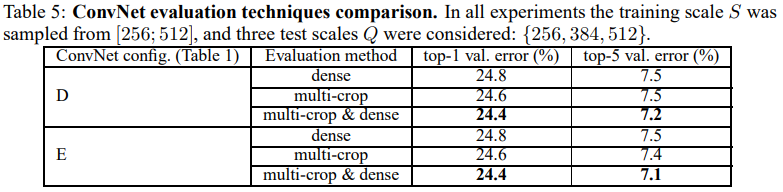
- 위의 표는 평가할 때 Dense와 multi-crop을 사용할 때의 결과이다.
- Dense를 사용했을 때 보다 multi-crop을 사용한 평가방법이 미세하게 성능이 더 좋음을 확인할 수 있고, 두 방식을 함께 적용하는 편이 가장 좋음을 볼 수 있다.
- 논문에서는 Dense evaluation과 방식은 Convolution 경계조건을 다르게 처리하기 때문에 두 방법 모두를 사용하면 서로 상호보완적이 되어 성능이 향상된다고 언급하고 있다.
4) 기타

- ILSVRC에 제출한 결과는 7개의 네트워크를 활용해 top-5 error 7.3%를 달성했으며, 제출 후 추가적인 실험을 통해 2개의 네트워크에서 top-5 error를 6.8%까지 낮췄다.
- 이 수치는 ILSVRC-2014의 SOTA인 GoogLeNet의 6.7%와 매우 근소한 차이입니다. 또, ensemble 없는 singel network에서는 7.0%로 7.9%의 GoogLeNet보다 더 좋은 성능을 보여준다.
VGGNet 정리
- VGGNet 은 모델의 깊이 늘림으로써 성능을 향상시킨다는 딥러닝의 컨셉을 충실하게 표현한 모델
- 단순한 구조로 이해와 구현이 쉽고 여러 형태로 변형시켜가며 테스트하기 용이하기 때문에 GoogLeNet보다 더 많이 사용
- 작은 필터를 사용함으로써 더 많은 ReLU함수를 사용할 수 있고 더 많은 비선형성을 확보