CNN based Models : MobileNet 모델에 대한 정리
MobileNet 개요
-
Xception의 아이디어를 기반하여 2017년 Google에 의해 설계됨
-
이전까지는 ResNet과 같이 네트워크의 크기를 키워서(파라미터 수를 늘려서) 성능을 높이는 방법에 주력했다면 Xception은 파라미터를 효율적으로 활용하여 성능을 높이는 방법을 생각함
-
MobileNet은 Xception에서 사용된 Deepthwise Separable Convolution이 연산효율이 좋은점을 활용하여 모바일 기기에서 동작 가능 할 정도로 경량한 네트워크를 설계하는데 집중함
-
Google에서 오픈소스로 제공하기 때문에 classification, detection, segmentation, pose estimation 등 다양한 컴퓨터 비전 모델에 사용되고 있음
-
2017년 발표 이래 매년 업그레이드하여 V2(2018) ~ V4(2024) 버전까지 나옴
-
Paper: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Depthwise Separable Convolution
- MobileNet의 주요 아이디어로써 Xception에서 사용된 DSC의 수정버전(extreme Inception)이 아니라 오리지널 DSC인 depthwise conv → pointwise conv 로 구성되며 중간에 비선형함수가 추가된 것을 사용함
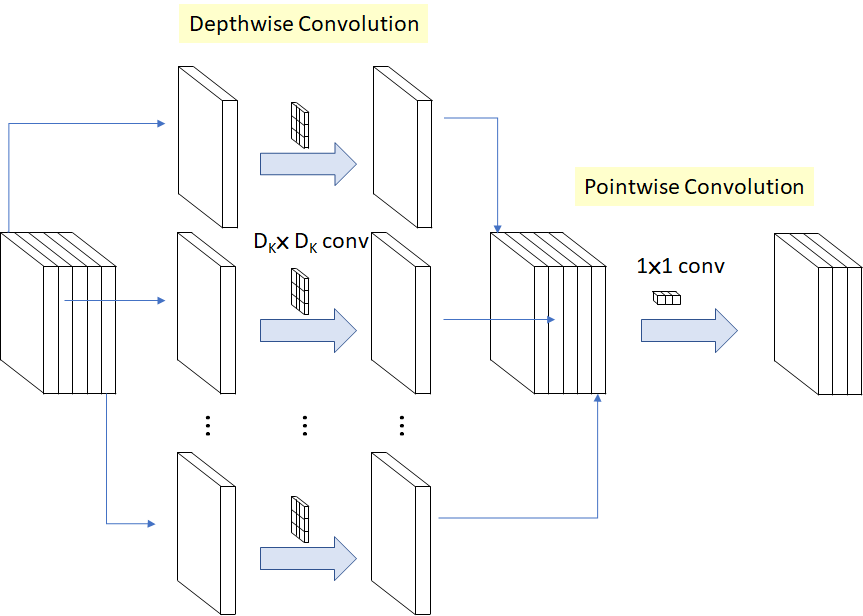
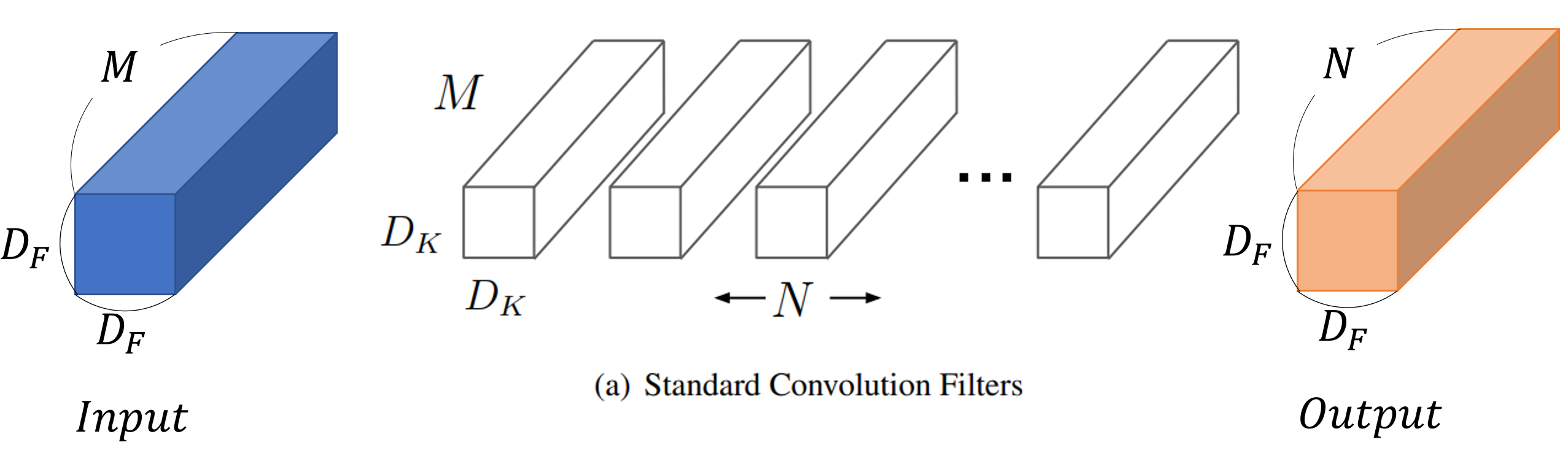
Standard Convolution 연산량
- 일반적인 Convolution layer에서 연산량은 입력해상도와 커널의 크기, 입/출력 채널을 모두 곱한 횟수만큼의 연산이 필요함
Depthwise Separable Convolution 연산량
- Depthwise 와 Pointwise 각각 연산량을 구해 더해본다.

Depthwise Conv. 연산량
- 각 채널별 1채널의 필터가 적용되므로 아래와 같은 연산량을 같는다.
Pointwise Conv. 연산량
- 오직 채널에 대한 분석이므로 입력/출력 채널 수에 입력 해상도를 곱한 값이 된다.
Depthwise Separable Conv. 연산량
- Depthwise 와 Pointwise 각 연산량을 합한 것
- 이때, Standard Convolution과 DSC의 연산량 감소 비율은 다음과 같이 계산할 수 있다.
- 연산량 감소 비율식을 보면 채널수()와 커널크기()가 영향을 미친다는 것을 알 수 있음.
- ex) , 일때 . 즉 약 9배 차이남
MobileNet 구조
- MobileNet은 Standard Convolution과 DSC를 섞어서 하나의 네트워크를 구성함.
- 아래 그림의 왼쪽을 보면 MobileNet에서 사용한 DSC 구조를 알 수 있다.
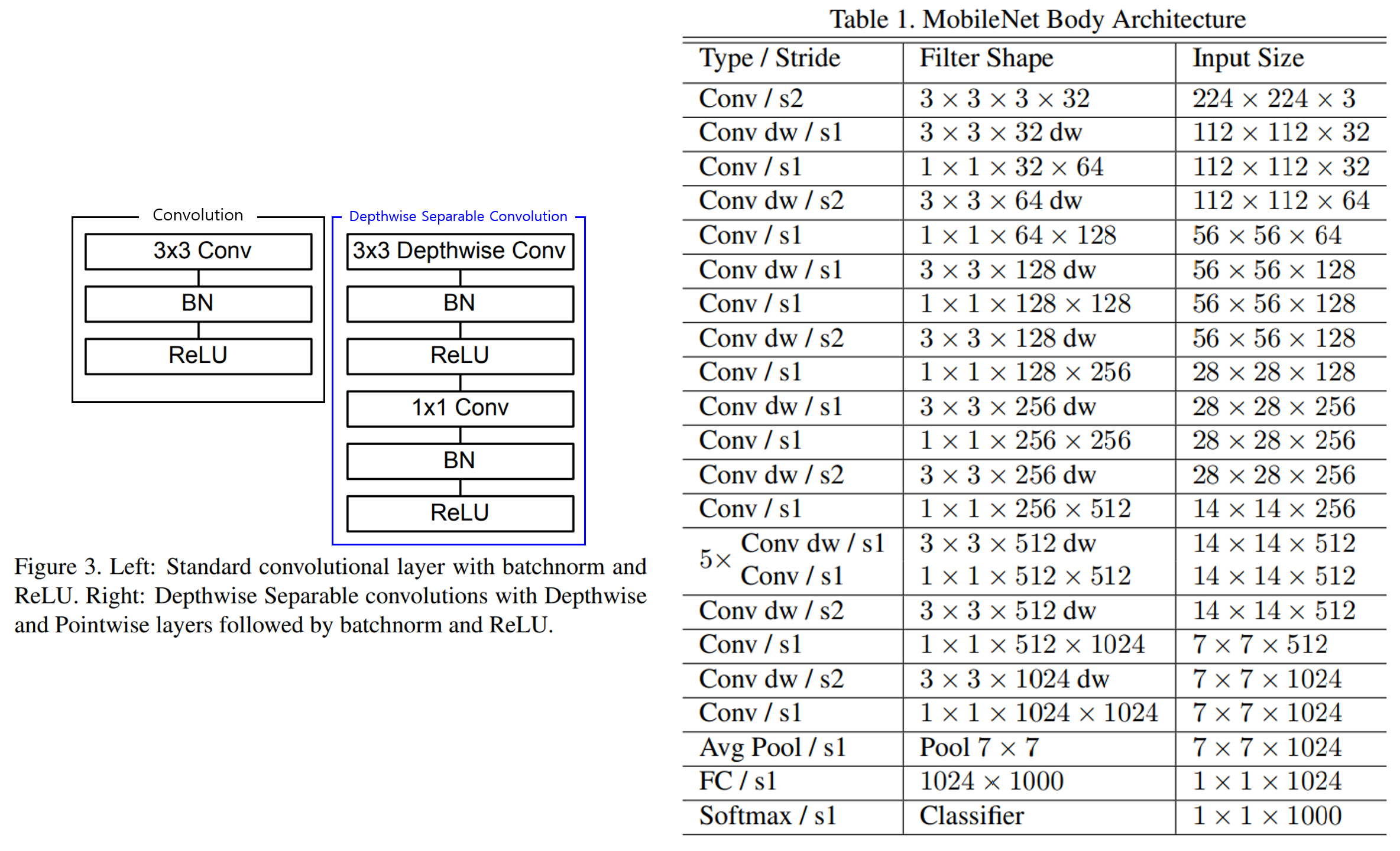
- 위 그림의 오른쪽은 MobileNet의 전체 구조로,
Conv dw는 DSC를 의미 하며s1,s2는 각각 stride=1, stride=2 의미한다. - 첫 번째 conv를 제외하고 DSC를 사용함. 마지막 FC 레이어를 제외하고 모든 레이어에 BN, ReLU를 사용한다. Down-sampling은 depthwise convolution과 첫 번째 conv layer에서 수행하며 총 28 레이어를 갖는다.
주목해야할 점
- Xception에서 소개된 extreme Inception과는 다르게 depthwise와 pointwise convolution의 각각 뒤에 Batch Normalization과 ReLU를 붙여줌.
- DownSampling을 할 때 일반적으로 사용되는 Pooling Layer를 따로 사용하지 않고 stride를 2로 잡아 차원 축소와 정규화 효과를 내도록 했다. 이는 계산 비용을 줄이고 공간 해상도를 유지하며 네트워크를 정규화하기 위함이라 설명함.
Hyper Parameter of MobileNet
- MobileNet은 그 자체로도 이미 경량화 되어 있지만 상황에 따라 더 경량화된 네트워크를 사용하기 위해 두 개의 Hyper-parameter 활용해 네트워크 크기를 더욱 줄일 수 있게 만들었다.
Width Multiplier: Thinner Models
- Width Multiplier 파라미터는 값을 이용해 모델의 채널 수(두께)를 줄인다.
- Conv Net에서 두께는 각 레이어에서 필터의 개수를 의미함.
- 연산량은 입력채널 과 출력채널(필터개수) 에 를 적용하여 아래의 식과 같이 나타냄.
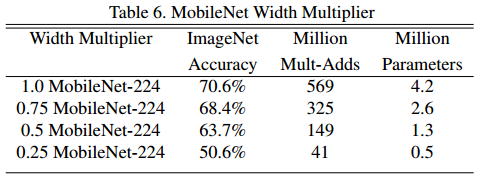
- 이때, 의 값은 0~1 사이이며, 기본 MobileNet은 1로 설정했고 값에 따른 결과는 아래와 같음.
Resolution Multiplier: Reduced Representation
- 네트워크 입력의 해상도를 줄이는 파라미터로, 가 입력 해상도에 해당하는 에 곱해져 연산횟수를 줄임.
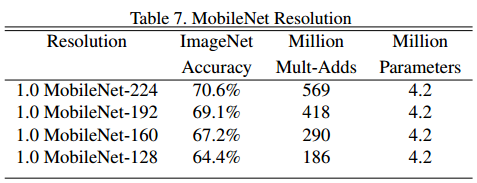
- 또한 0~1 사이 값을 가지며 해상도에 따른 결과는 아래와 같음.
성능평가
1) Full Conv vs. Depthwise Separable Conv
- DSC를 사용했을 때 얼마나 효율적인지 비교하기위해 MobileNet 구조에서 DSC를 모두 일반 conv레이어로 교체한 것과 비교함.
- ImageNet 데이터셋으로 평가했으며, MobileNet이 Full Conv 모델보다 파라미터 수와 연산 횟수가 압도적으로 적지만 성능은 약 1% 떨어지는 것을 확인함.

2) Hyper Parameter에 따른 변화
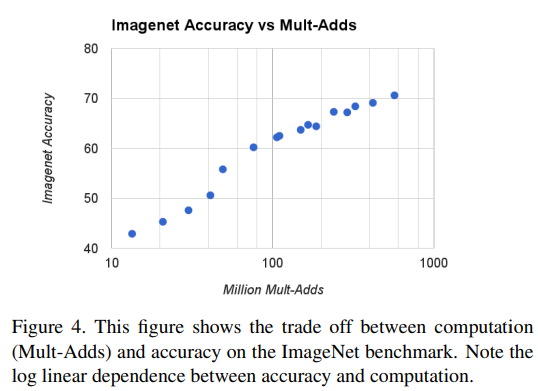
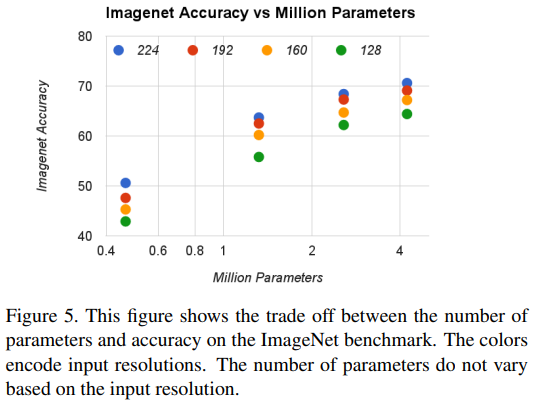
- 위의 하이퍼 파라미터에 따른 결과 변화에서 연산량과 정확도를 그래프로 나타내면 아래와 같음.
- 연산량과 성능 사이의 상관관계를 로그선형 형태를 보여주므로, 두 하이퍼 파라미터의 조절이 성능과 연상량/파라미터 수 사이의 적절한 Trade off를 수행함을 알 수 있음.
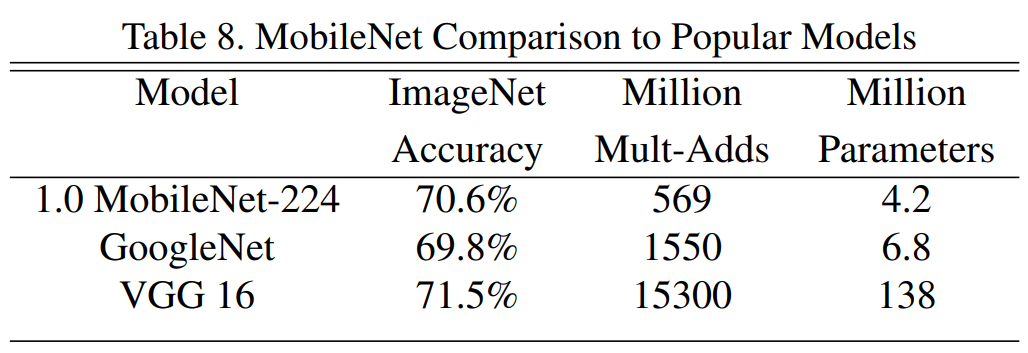
3) 다른 네트워크와 비교
- MobileNet은 VGG-16보다 32배나 가벼우며 27배나 연산량이 적지만 성능은 0.9%만 차이남.
- 심지어 연산량과 파라미터 수가 더 많은 GoogLeNet보다 높은 성능을 보여줌.
- 상대적으로 작은 모델인 SqueezeNet, AlexNet과 비교하여 MobileNet은 SqueezeNet보다 22배 연산량이 적고 AlexNet보다 45배 가볍지만 두 모델보다 4%정도 높은 성능을 보여줌.

4) 다른 테스크에서의 성능
- Image Classification 분야 뿐만아니라 다른 테스크에서도 좋은 성능을 보이지는 확인함.
Fine-Grained Recognition
- Fine-Grained Recognition은 보다 세밀한 classification으로서 Standford Dogs dataset을 예로들면, 강아지이미지가 주어졌을 때 Dog classs인지 뿐만 아니라 어떤 품종(허스키인지 푸들인지)인지까지 맞추는 분야.
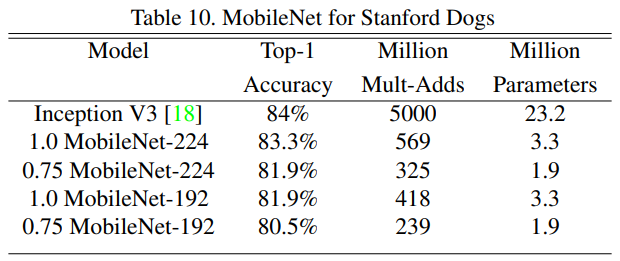
- Standford Dogs dataset에서 Inception V3 모델과 MobileNet을 비교한 결과 아래와 같다.
- MobileNet 기본형(α와 ρ가 모두 1)이 Inception V3와 유사한 성능을 보여주면서 연산량과 파라미터 수를 엄청나게 줄인것을 볼 수 있다.
Object Detection
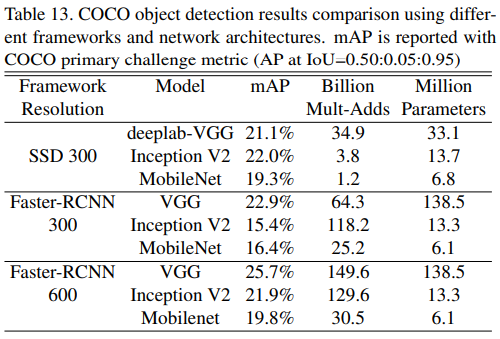
- Object detection은 이미지 안에서 물채를 찾아내고 그 물체가 어떤 class에 속하는지까지 분류하는 문제로, YOLO, SSD, Faster-RCNN등이 있다.
- Object detection을 위한 네트워크는 크게 세 부분으로 나뉘며, 1)Feature map을 추출하는 CNN Network인 Backbone과 2)Backbone에서 나온 feature map을 정제하는 Neck, 그리고 3)물체의 위치를 찾는 Head로 이루어져 있다.
- 실험은 Backbone을 VGG, Inception V2, MobileNet으로 바꿔가며 COCO dataset에 대해 평가함.
- MobileNet은 모든 경우에 더 적은 파라미터와 연산량을 사용하지만 다른 Backbone과 어느정도 유사한(하지만 낮은) 성능을 보여줌.
결론
- MobileNet은 Convolution과 Depthwise Separable Convonlution을 쌓아 올려가는 단순한 구조에, 네트워크의 크기를 조절할 수 있는 hyper-parameter까지 제안하여 하드웨어 환경이 열악한 모바일 기기에서도 유연하게 적용할 수 있는 네트워크이다.
- 성능평가에서 연산량과 파라미터 수는 적지만 다른 큰 네트워크 대비 유사한 또는 더 좋은 성능을 보여줌.
- hyper-parameter를 조절해 연산량과 성능 사이의 trade-off가 잘 이뤄짐을 보여줌.
- 연산량과 파라미터 수가 엄청나게 줄었지만 어느정도 좋은 성능을 보여주는 효율적인 네트워크로서, 이후 V2, V3 버전으로 발전해 가며 대표적인 경량화 네트워크로 자리잡음.