딥러닝 기반의 Object Detection(객체 검출) 모델의 기본 원리 및 잘 알려진 모델 정리
Object Detection
개요
- Object Detection(객체 검출)이란 이미지 내에서 물체의 위치(localization) 와 그 종류(classification) 를 찾아내는 것으로 다양한 이미지 기반 문제에 필수적으로 사용됨.
- 즉, classification과 localizaion을 동시에 수행하는 것을 의미하고, 하나의 객체뿐만 아니라 여러 객체(multiple object)도 찾을 수 있어야 한다.
- 일반적으로 Object Detection의 결과는 검출된 객체의 종류(class)와 위치 박스(bounding-box)를 반환한다.

Classification with Localization

- 기존 CNN based Models에서 이미지에 대한 class 정보와 함께 위치 정보(Bounding-Box)를 함께 학습되도록 하면 객체의 종류와 위치를 함께 출력하도록 할 수 있다.
- 기존 Classification 모델에서 아래와 같이 출력되도록 최종 레이어를 수정하여 사용할 수 있지만, 이미지에서 하나의 객체에 대해서만 검출할 수 있다는 단점을 가진다.
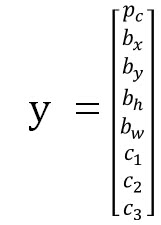
- : object가 있을 확률
- : 각 클래스에 속할 확률
- : object의 위치 박스
Sliding Window & Convolution
Sliding Window

- 기본적인 Sliding Window 방법으로는 기존의 classification 모델을 여러 크기의 윈도우를 이미지에 슬라이딩하여 가장 높은 확률값의 위치를 찾음으로써 localization을 수행할 수 있지만 이런 방법은 매우 높은 계산 비용과 시간을 요구함.
- 이러한 문제점을 해결하기 위해 Convolution을 이용한 Sliding Widow 방법을 제안함.
Fully Connected to Convolution
- 기존의 FC(Fully Connected) 층을 Convolution으로 바꾼 형태.
- 아래는 FC 층을 Convolution 층으로 변경한 그림이다.

- 위 그림에서 상단 FC 층을 사용한 방법은 14x14x3 이미지를 입력으로 받고, Convolution 층과 Max Pooling 층을 거쳐 5x5x16 출력을 flatten 시켜 400개 유닛에 대한 FC를 수행한 뒤 Softmax를 거쳐 4개 클레스에 대한 확률을 반환한다.
- 하단은 FC 층을 Convolution 층으로 변경한 것 이다. Max Pooling의 결과 까지는 같고, 5x5x16 필터 400개를 이용해 1x1x400 출력을 만들며 이는 FC와 수학적으로 같다. 다음으로 1x1x400 필터 400개를 이용해 Convolution 하면 똑같이 1x1x400이 되고 이것 또한 FC와 동일하다.
Sliding window with Convolution
- 2013 발표된 OverFeat 모델은 Convolution으로 Sliding Window를 구현하였다.


- 위의 예시를 보면 Convolution 모델의 입력 크기가 14x14x3 일 때, 데이터셋의 이미지는 16x1OverFeat6x3 임을 가정한다. 16x16 이미지를 4개의 영역으로 나누어 각각 객체의 존재에 대해 학습하고 싶을 때, 기존의 방법은 분리한 4개의 영역에 대해 14x14 컨볼루션 모델을 모두 각각 학습하여야 한다.
- 하지만, Sliding Window로 구현된 Convolution은 4번의 학습 계산들을 공유할 수 있게 한다. 즉, 위 그림과 같이 동일한 필터들(가중치들)을 사용했을 때, 16x16x3 이미지가 입력되면 최종 출력은 2x2x4가 되고, 이때 2x2에서 각 셀의 결과는 16x16x3 이미지를 14x14x3 크기로 잘라서 각각(독립적으로) 학습한 결과와 같게 된다.
- 즉, 제시한 컨볼루션 구조를 이용하면 14x14보다 큰 이미지를 입력으로 받을 때, 14x14 영역으로 각각 crop하여 독립적으로 학습을 수행하였을 때의 결과를 한꺼번에 반영하는 결과를 출력할 수 있다.

- 만약 위 그림처럼 28x28x3 이미지가 입력으로 들어온다면, 입력 이미지를 14x14 크기에 stride=2로 슬라이싱하여 총 8x8의 영역에 대한 결과가 반영되는 확률맵이 출력된다.
Object Detection Models
SOTA of Object Detections
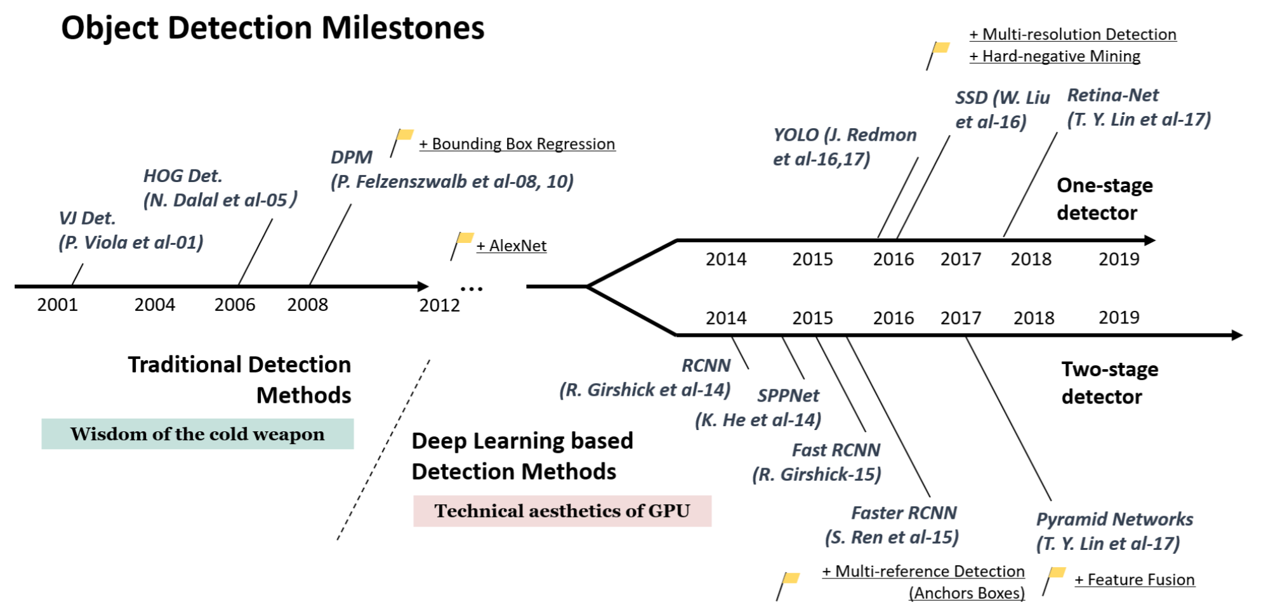
- 2012년 이전 전통적인 이미지처리 방법으로 Object Detection이 발전해 왔다면, 2012년 AlexNet과 CNN의 효과가 검증된 이후 RCNN, YOLO 등 다양한 Deep-learning based Object Detection 방법들이 연구됨.
One-stage & Two-stage
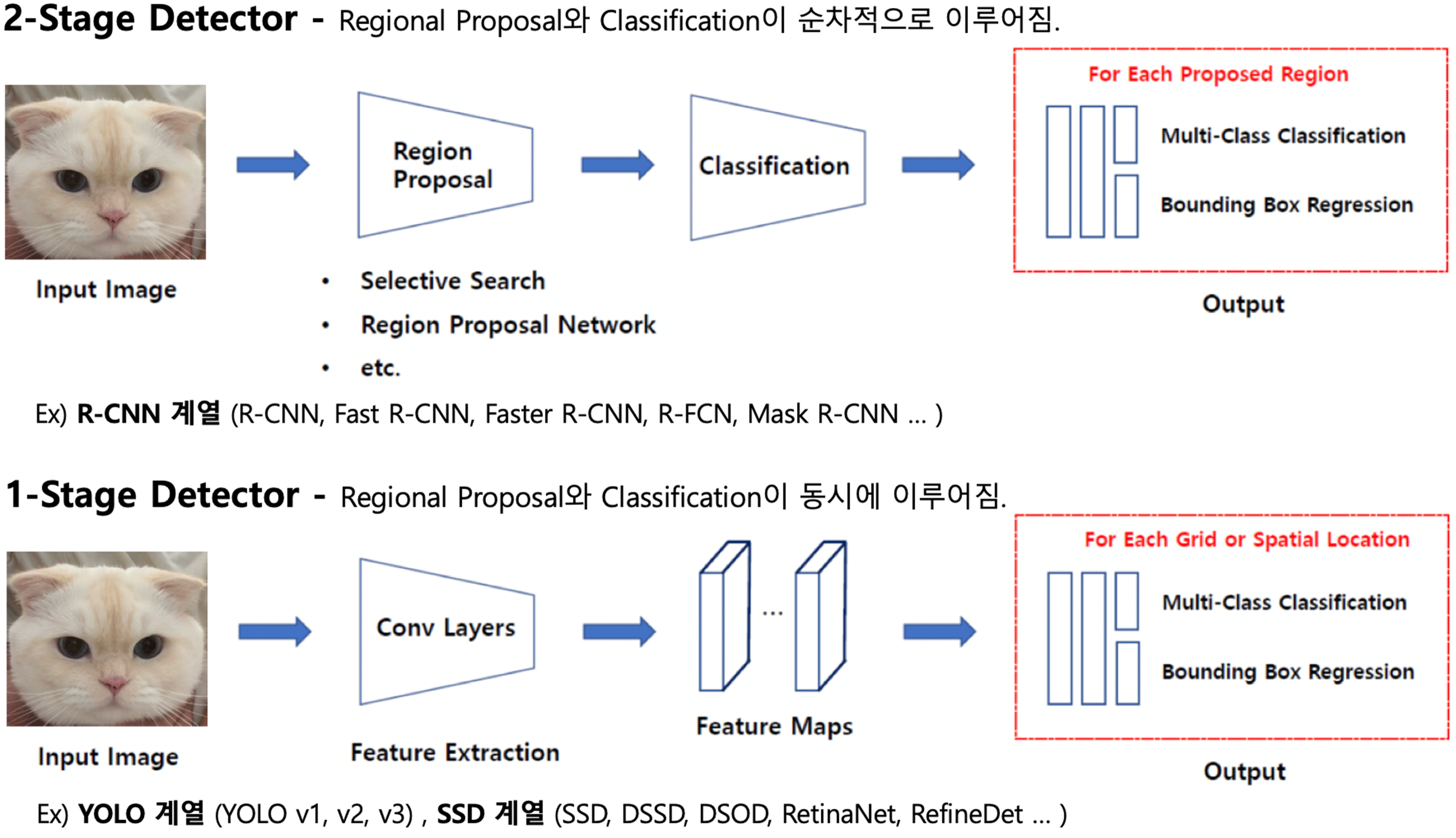
2-Stage Detection
- 객체가 있을 법한 후보 영역을 생성하는 영역 제안(Region Proposal) 과정과 제안된 영역에 대해 객체의 클래스와 박스 좌표를 예측하는 Classification + Regression 과정이 순차적으로 이루어짐.
- 상대적으로 높은 정확도를 보여주는 대신에 두 단계의 처리로 인해 연산량이 많아 속도가 느리다.
1-Stage Detection
- 단일 네트워크에서 입력 이미지로부터 바로 객체의 클래스와 위치를 예측함.
- 모든 예측이 하나의 계산(forward)에서 이루어지므로 속도가 빠른 대신에 상대적으로 정확도가 낮을 수 있다.
요약
| 항목 | One-Stage | Two-Stage |
|---|---|---|
| 검출 단계 | 단일 단계 (End-to-End) | 두 단계 (Region Proposal + Classification) |
| 속도 | 빠름 (실시간 가능) | 느림 (추가 연산 필요) |
| 정확도 | 상대적으로 낮음 | 상대적으로 높음 |
| 대표 알고리즘 | YOLO, SSD, RetinaNet | Faster R-CNN, Mask R-CNN |
| 적용 분야 | 실시간 시스템, 경량화된 환경 | 정밀도가 중요한 응용, 복잡한 장면 |
Models
13-0. NMS (Non Maximum Suppression)
13-1. R-CNN
13-2. Overfeat
참고
- cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
- Lecture 11 | Detection and Segmentation - YouTube
- 딥러닝 Object Detection(1) - 개념과 용어 정리
- 딥러닝 가이드 - Object Detection
- [Object Detection] Sliding Windows Detection
- 12. Survey on Deep Learning Object Detection - Deep Learning Bible - 4. Object Detection - 한글