Object Detection 시리즈 : R-CNN 모델에 대한 정리
R-CNN 개요
-
R-CNN(Regions with Convolutional Neural Networks)은 설정한 Region(지역)을 CNN의 feature(입력값)으로 활용하여 Object Detection을 수행하는 신경망.
-
객체의 위치를 찾고(Regoin proposals), CNN기반 class를 분류(Classification)를 순차적으로 진행하는 대표적인 2-stage detector 모델로서, CVPR 2014에서 소개되며 초기 딥러닝 기반의 Object Detection 발전에 가장 많은 영향을 미침.
-
R-CNN 논문의 초기 버전은 Overfeat보다 한달 빠른 2013년 11월에 업로드 되어 최초의 CNN기반 Object Detection 모델이라 할 수 있다.
-
OverFeat의 Sliding Window 방법과 달리, R-CNN은 Selective Search를 사용해 이미지에서 제안된 후보 영역(Region Proposals)을 먼저 추출한 뒤, CNN을 활용해 각 영역을 분류하고 바운딩 박스를 조정하는 방법.
-
paper: Rich feature hierarchies for accurate object detection and semantic segmentation
Key-Points
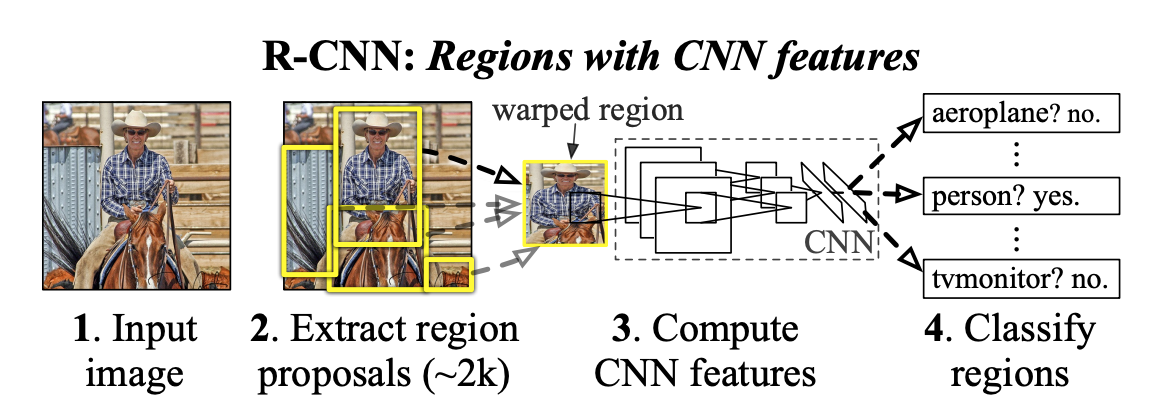
- Selective search 알고리즘을 통해 객체가 있을 법한 위치인 후보 영역(region proposal)을 2000개 추출하여, 각각을 227x227 크기로 리사이즈함.
- 리사이즈된 모든 region proposal을 Pre-trained Alex Net 에 입력하여 2000x4096 크기의 feature vector를 추출함.
- 추출된 feature vector를 linear SVM 모델과 Bounding box regressor 모델에 입력하여 각각 confidence score와 조정된 bounding box 좌표를 얻는다.
- 마지막으로 NMS 알고리즘을 적용하여 최적의 bounding box를 출력함.
방법
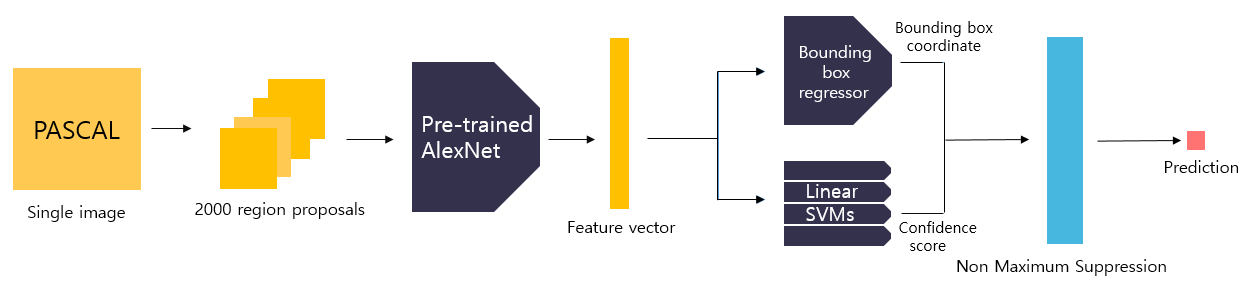
1. Region proposal by Selective Search

- R-CNN 모델은 구체적인 객체의 위치를 추정하기 앞서 Selective search 알고리즘을 통해 객체가 있을법할 위치인 후보 영역(Region proposal) 을 추출.
- Selective search 알고리즘은 색상, 무늬, 명암 등의 다양한 기준으로 픽셀을 grouping하고, 점차 통합시켜 객체가 있을법한 위치를 bounding box 형태로 추천함.
- R-CNN 에서는 단일 이미지에서 2000개의 후보 영역을 추출한 뒤, CNN 모델에 입력하기 위해 227x227 크기로 리사이즈(resize) 시킨다.
- 저자는 후보 영역 주변 16픽셀을 포함하여 가로 세로 비율을 고려하지 않고 resize 시켰다고 함.
Selectivce search paper : Selective search for object recognition. IJCV, 2013
2. Feature extraction by Fine tuned AlexNet
- 2000개의 후보영역을 Pre-training된 AlexNet 에 입력하여 2000(=후보 영역의 수)x4096(=feature vector의 차원) 크기의 feature vector를 추출한다.
- Pre-trained AlexNet은 ImageNet 데이터셋을 이용하여 사전훈련된 모델이고, 목표하는 도메인에 맞게 fine tuning하는 방식을 추천함.
Pre-trained AlexNet
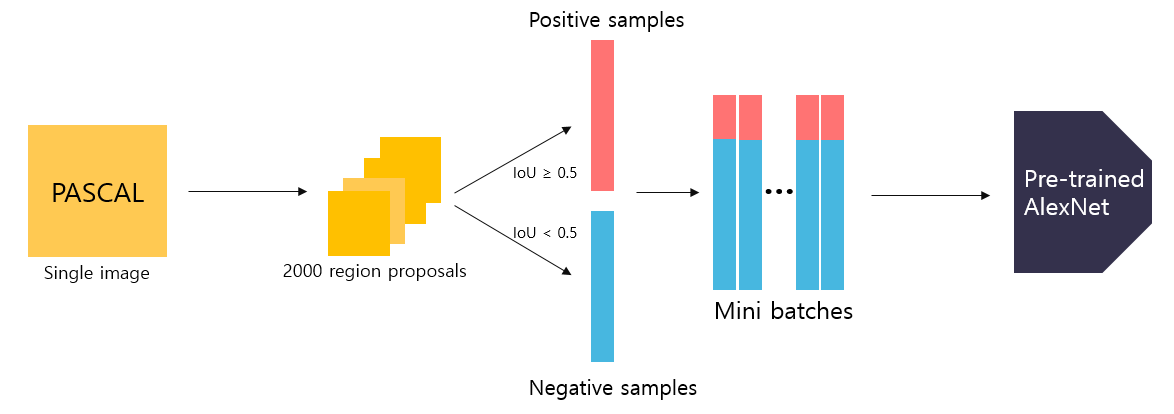
- R-CNN 모델이 추론 시 입력으로 들어온 region proposal은 객체일 수도, 배경일 수도 있다. 따라서 CNN 모델을 fine tuning 할 때 예측하려는 객체의 수가 N개라고 하면, 배경을 추가하여 (N+1)개의 class를 예측하도록 모델을 설계(output=N+1) 해야 하며 객체와 배경을 모두 포함한 학습 데이터를 구성해야함.
- R-CNN은 PASCAL VOC 데이터셋에 Selective search 알고리즘을 적용하여 후보 영역을 추출하고, 후보 영역과 ground truth box의 IoU 값을 구해 0.5 이상인 경우 positive sample(=객체)로, 0.5 미만인 경우 negative sample(=배경)로 저장함.
- 이 후, positive sample=32, negative sample=96 으로 mini batch=128를 구성하여 ImageNet으로 사전훈련된 Pre-trained AlexNet에 fine tuning 학습을 진행함.
3. Classification by linear SVM
- linear SVM 모델은 2000x4096 feature vector를 입력 받아 class를 예측하고 confidence score를 반환함.
- linear SVM는 특정 클래스에 해당하는지 여부만을 판단하는 이진 분류기(binary classifier) 이기 때문에 N개의 클래스를 예측한다고 할 때, 배경을 포함한 (N+1)개의 독립적인 linear SVM 모델을 학습 시켜야 한다.
- R-CNN이 Classifier로 Softmax 함수를 쓰지 않고 SVM을 사용한 이유는 VOC2007 데이터셋을 기준으로 Softmax를 사용였을 때 mAP 값이 54.2%에서 50.9%로 하락했다고 함.
Training linear SVM using fine tuned AlexNet
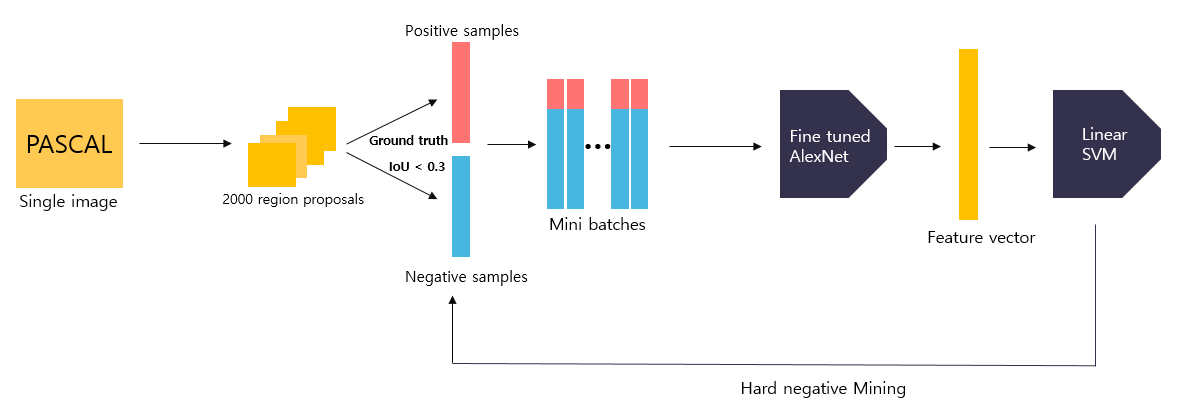
- 객체와 배경을 모두 학습하기 위해 PASCAL VOC 데이터셋에 Selective search 알고리즘을 적용하여 후보 영역을 추출한다. 이 때, AlexNet을 fine tuning 할 때와 다르게 오직 ground truth box만을 positive sample로, IoU 값이 0.3 미만인 예측 bounding box를 negative sample로 저장한다. (테스트 결과 가장 나았음)
- 위 그림과 같이 positive sample=32, negative sample=96 이 되도록 minibatch=128을 구성하고 fine tuned AlexNet에 입력하여 feature 해 vector를 추출하고, 이를 SVM에 입력하여 학습시킨다.
- 하나의 SVM 모델은 특정 class의 유무를 판별하기 때문에 output=2가 되며, 학습이 한 차례 끝난 후 hard negative mining 기법을 적용하여 재학습시킨다.
Hard Negative Mining
[그림]
- Hard Negative Mining이란 모델이 예측에 실패하는 어려운(hard) sample들을 모으는 기법으로, 이 방법을 통해 수집된 데이터를 활용하여 모델을 보다 강건하게 학습시키는 것이 가능해진다.
- 모델은 주로 Fasle Positive (객체가 아닌데, 객체라 판단함) 오류를 보이며, 이는 객체 탐지 시 객체의 위치에 해당하는 positive sample 보다 배경에 해당하는 negative sample이 훨씬 많은 클래스 불균형(class imbalance)에 의해 발생함.
- 이러한 문제를 해결하기 위해 모델이 잘못 판단한 False Positive sample을 학습 과정에 추가하여 재학습함으로써 모델을 보다 강건하게 만든다.
- 학습된 linear SVM에 2000x4096 크기의 feature vector를 입력하면 class와 confidence score를 반환한다. (학습된 SVM 모델은 클래스 개수 만큼 존재함, Fast R-CNN 부터는 softmax를 사용하여 end-to-end 학습함)
4. Bounding Box Regression
- Selective search로 찾은 Bounding box는 정확하지 않을 수 있기 때문에 box의 좌표를 변환하여 객체의 위치를 세밀하게 조정해주는 Bounding box regressor 모델을 사용한다.
- Bounding box regressor 모델은 예측된 box 좌표 와 정답 박스 좌표 의 차이가 최소가 되도록 변환하는 를 학습한다.
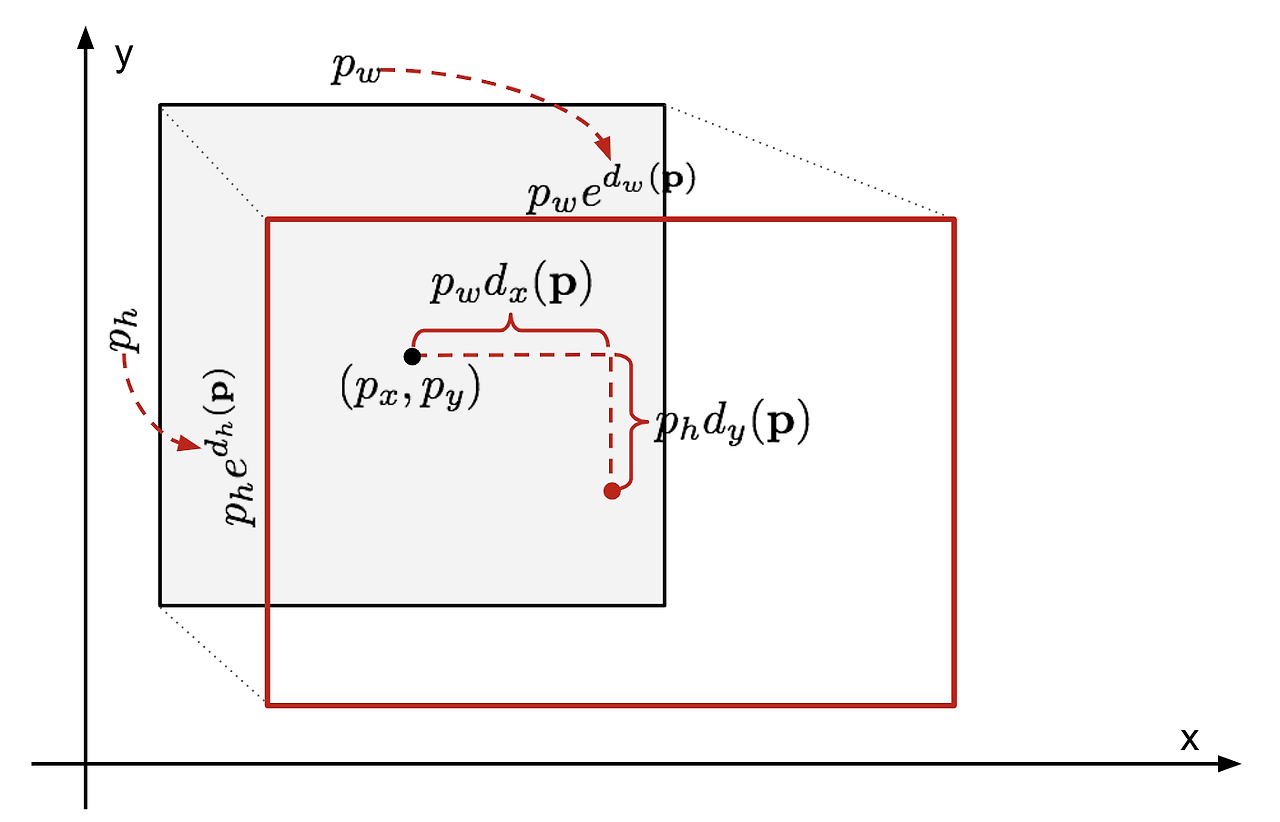
- Selective search에 의해 예측된 box 좌표를 , 정답 box 좌표를 라고 하며, 위 그림에서는 가 회색 박스, 가 빨간색 테두리 박스를 나타낸다.
- 을 regressor 모델이 예측한 박스, 는 모델이 예측한 변환 벡터, 는 를 로 변환하는 벡터를 의미함. 따라서, 와 의 차이를 줄이는 방향으로 학습 하는 것이 목표.
- 이 때, 모델은 스케일 불변의 변환(Scale invariant Transformation)을 학습하며, width와 height는 지수함수를 이용해 업데이트된다.
- AlexNet의 5번째 Conv Layer에 Pooling이 적용된 출력()을 Bounding box regressor 모델에 입력 feature로 사용하여 ridge regression을 진행함.
- 오버피팅과 모델의 일반화 능력을 향상 시키기 위해 L2 Regulatization 항을 추가함.(, )
Training Bounding Box regressor using fine tuned AlexNet
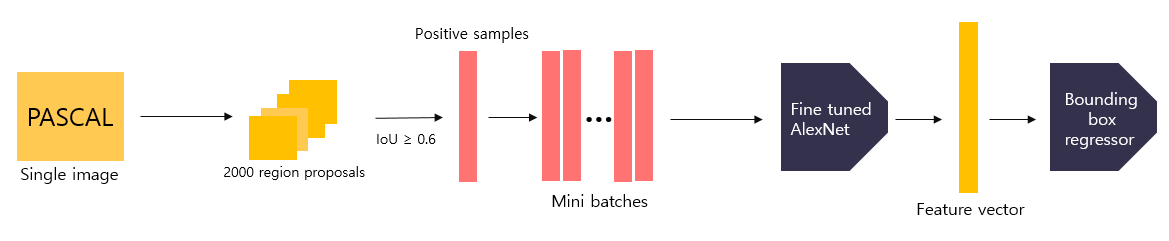
- PASCAL 데이터셋에 Selective search 알고리즘을 적용하여 얻은 후보 영역을 학습 데이터로 사용한다.
- 별도의 negative sample은 정의하지 않고, IoU 값이 0.6 이상인 sample을 fine tuned AlexNet에 입력으로 넣어 5번째 Conv Layer에 Pooling이 적용된 출력(feature vector)를 box regressor에 입력하여 학습을 시켰다.
- box regressor는 feature vector를 입력 받아 조정된 bounding box 좌표값 4개를 반환한다.
5. NMS (Non Maximum Suppression)

- 최종적으로 linear SVM을 통해 얻은 confidence와 box regressor을 통해 얻은 box 좌표를 이용해서 NMS 후처리를 통해 box를 필터링함.
- (NMS 알고리즘 참고) R-CNN 에서는 Class-Aware NMS (클래스마다 NMS 적용) 방법을 사용하며, 기본적으로 confidence threshold=0.5, IoU threshold=0.3 를 설정하였다.
정리
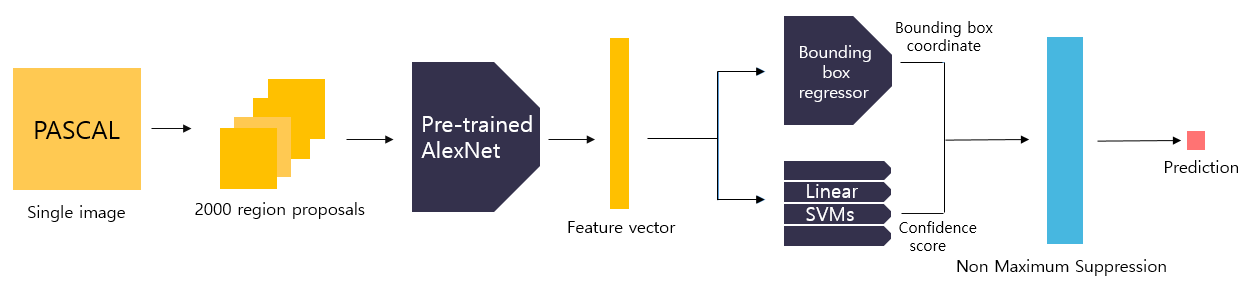
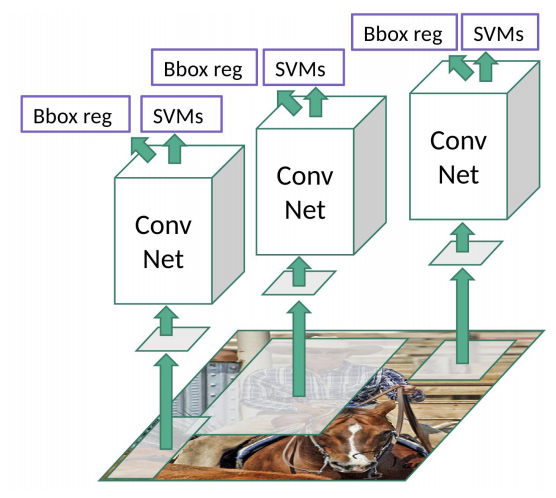
- 최종적으로 R-CNN의 흐름은 위 그림과 같다. Object detection을 수행하기 위해 딥러닝 구조를 처음 사용했다는 점에서 의의가 있다.
- Selective search를 사용하여 이미지 한 장당 2000개의 후보 영역을 추출하다보니 속도가 느리고 AlexNet, SVM, Box regressor 등 3개의 독립적인 네트워크를 사용하므로 학습이 까다롭고 복잡한 구조를 가진다는 단점이 있다.
- 이후, R-CNN의 단점을 보완한 end-to-end 학습 방식의 Fast R-CNN, Faster R-CNN이 연구되었다.