Mean Shift 개요
- Mean Shift(평균 이동)는 K-Means와 유사하게 중심을 군집의 중심을 지속적으로 움직이면서 클러스터링을 수행한다. 다만, Mean Shift는 중심을 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킨다.
- 데이터의 분포도를 이용해 중심점을 찾는데, 확률 밀도 함수를 이용하고 이를 찾기 위해서 KDE(Kernel Density Estimation)을 이용한다.
- K-Means와 달리 군집의 개수를 지정할 필요가 없고, 비정형 데이터에는 한계가 존재하여 이러한 경우 DBSCAN을 이용한다.
 |  |
|---|
Mean Shift 방법
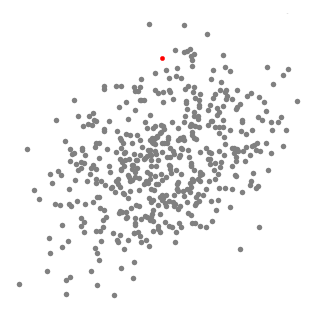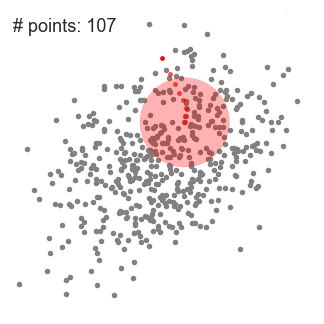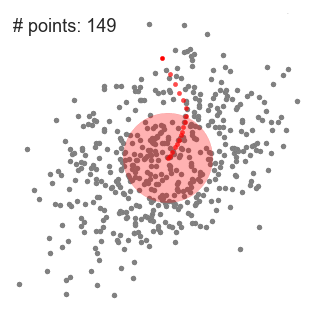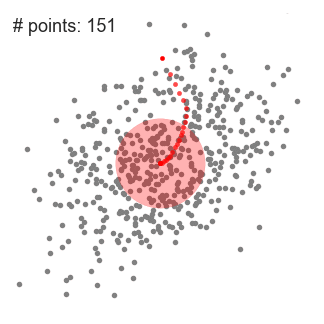
- 특정 데이터에서 반경 내의 데이터 분포 확률 밀도가 가장 높은 곳으로 이동하기 위해 주변 데이터와의 거리 값을 KDE 함수 값으로 입력한 뒤 그 반환 값을 현재 위치에서 업데이트하면서 이동하는 방식을 취한다.
알고리즘
- 특정 점 에서 반경 (bandwidth)를 갖는 윈도우(커널)을 설정한다.
- 윈도우 안의 모든 점들의 가중평균(Weighted Mean) 을 계산한다.
- 현재 점을 그 평균값으로 이동한다. 즉, Mean shift 벡터를 따라 점을 이동함.
- 밀도 최대 지점에 도달할 때까지 반복한다. (위치가 업데이트 되지 않을 때 까지 반복)
- 위 과정을 모든 개별 점들에 대해 적용함.
커널 함수 (Kernal Function)
- 수학적으로 커널함수는 원점을 중심으로 대칭이면서 적분 값이 1인 non-Negative 함수로 정의된다.
- 가우시안(Gaussian) Epanechnikov, uniform 함수 등이 대표적인 커널 함수.
- Uniform 커널: 윈도우 안 모든 점의 가중치가 동일 → 일반 평균
- Gaussian 커널: 중심에서 가까운 점일수록 큰 가중치, 멀수록 작은 가중치→ 가중 평균
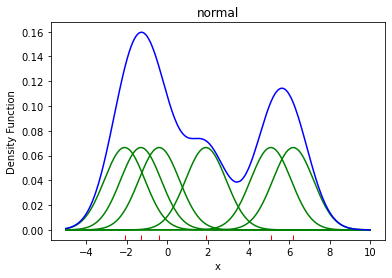
밀도 추정 (Kernel Density Estimation, KDE)
- KDE는 커널(kernel) 함수를 통해 어떤 변수의 확률 밀도 함수를 추정하는 대표적인 방법.
- 관측된 데이터 각각에 커널 함수를 적용한 값을 모두 더한 뒤에 데이터 건수로 나눠 확률 밀도 함수를 추정.
- 아래 그림에서 초록 선은 개별 관측 데이터에 가우시안 커널 함수를 적용한 것이고, 파란 선은 적용 값을 모두 더한 KDE 결과이다.
- 데이터 와 커널 함수 , 대역폭 가 주어졌을 때, KDE 추정식은 아래와 같다.
- : 데이터 차원
- : 커널 함수 (일반적으로 가우시안)
- : 대역폭
- 크면 멀리 있는 점도 큰 가중치 → 넓게 스무딩
- 작으면 가까운 점만 의미 있는 가중치 → 국소적 이동
- 즉, 데이터와의 거리 를 h로 나눠서 스케일링.
Gaussian 커널에서 h의 동작
Gaussian kernel:
- 는 사실상 표준편차(σ) 역할.
- 가 커질수록 거리값이 작아짐 → 거리값 대비 큰 가중치 → 멀리 있는 점들도 큰 가중치
가중 평균 계산
- 데이터를 라 하고 각 데이터의 가중치를 라 할 때, 가중평균 식은 아래와 같다.