DBSCAN 개요
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)은 데이터의 밀도(density)를 기반으로 클러스터를 형성하는 비지도 학습 알고리즘이다.
- 밀도가 높은 영역을 하나의 클러스터로 인식하고, 밀도가 낮은 지역은 노이즈(이상치)로 간주함.
- 기하학적으로 패턴이 있는 비정형 데이터 군집화에 유리하고, K-Means와 달리 군집의 개수를 정할 필요가 없다.
DBSCAN vs. K-Means

DBSCAN 방법
주요 하이퍼파라미터
- eps: (ϵ, epsilon) 클러스터를 구성하기 위한 최소 거리 (반지름)
- minPts: (minimum poinsts) 클러스터를 구성하기 위한 최소 데이터 포인트 수
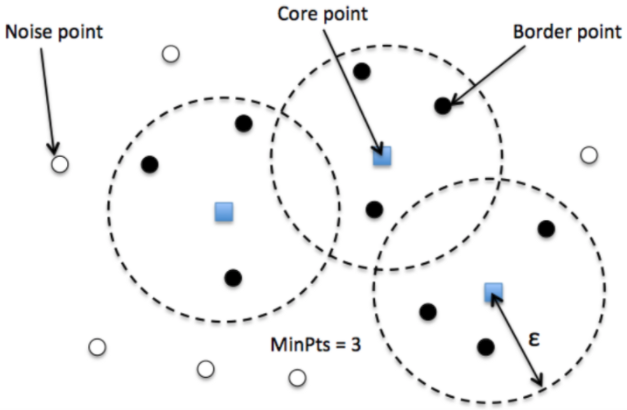
데이터 포인트 구분
- DBSCAN은 모든 데이터 포인트를 아래 3가지로 분류한다.
- Core Point: 특정 점을 중심으로 eps 반경내에 minPts 이상의 점이 있으면, 그 점을 Core Point라 함.
- Border Point: Core Point 클러스터 내에 포함되지만, 스스로는 Core Point를 만족하지 않는 점.
- Noise Point: Core Point와 Border Point 어느 클러스터에도 속하지 않는 점.
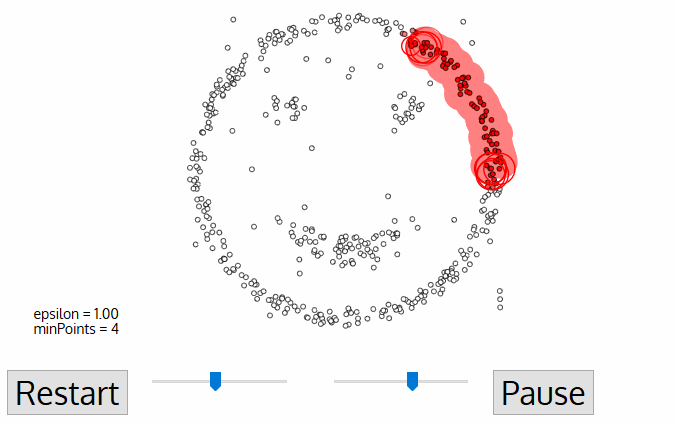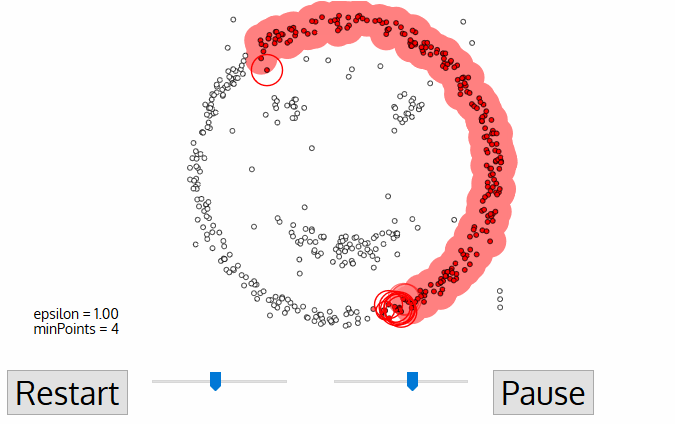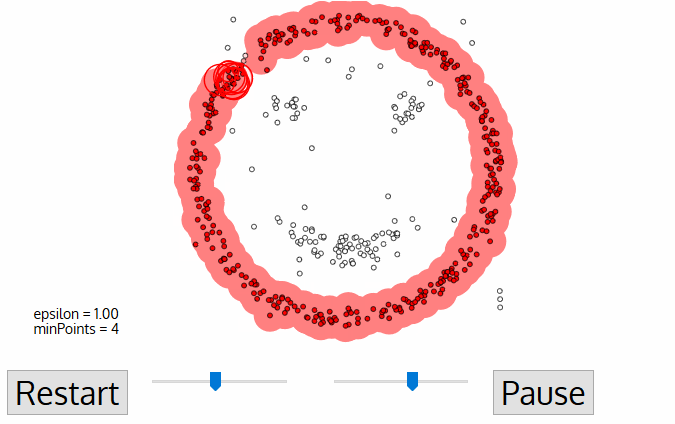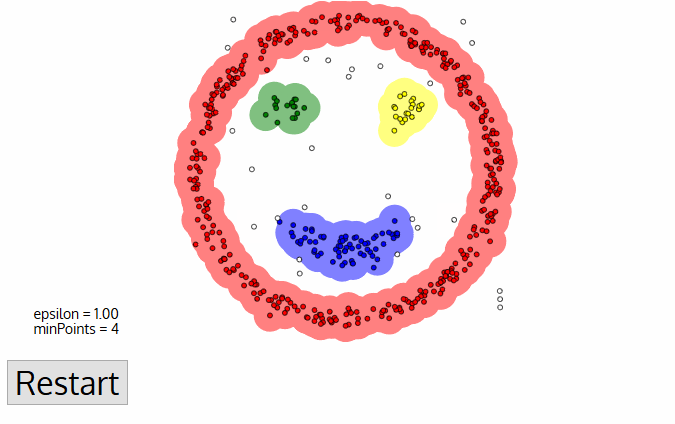
DBSCAN 알고리즘
- 임의의 데이터 포인트 선택
- 선택된 데이터 포인트과 eps 거리 내에 있는 모든 포인트 탐색
- 거리 내 포인트가 minPts 이상이면 선택된 데이터 포인트를 Core Point로 지정하고 클러스터 생성
- 거리 내 포인트가 minPts 미만: Core Point 포함 시 Border Point, 미포함 시 Noise Point로 지정
- 클러스터 안의 점들 중, 다른 클러스터의 Core Point가 되는 점이 존재한다면 두 클러스터는 하나의 클러스터로 설정함
- 모든 데이터 포인트에 대해서 1~3번 과정 반복
- 모든 포인트가 Core Point / Border Point / Noise Point 중 하나로 구분되면 종료
DBSCAN 사용 시 고려해야할 점
- 적절한 minPts 설정:
- 데이터셋의 크기가 크고, 노이즈가 많을 수록 minPts 값을 크게 잡는 것이 유리함.
- 도메인에 대한 지식이 있다면 이를 활용해서 설정 가능함.
- 일반적으로 minPts≥데이터 차원 수 (D)+1 로 설정함.
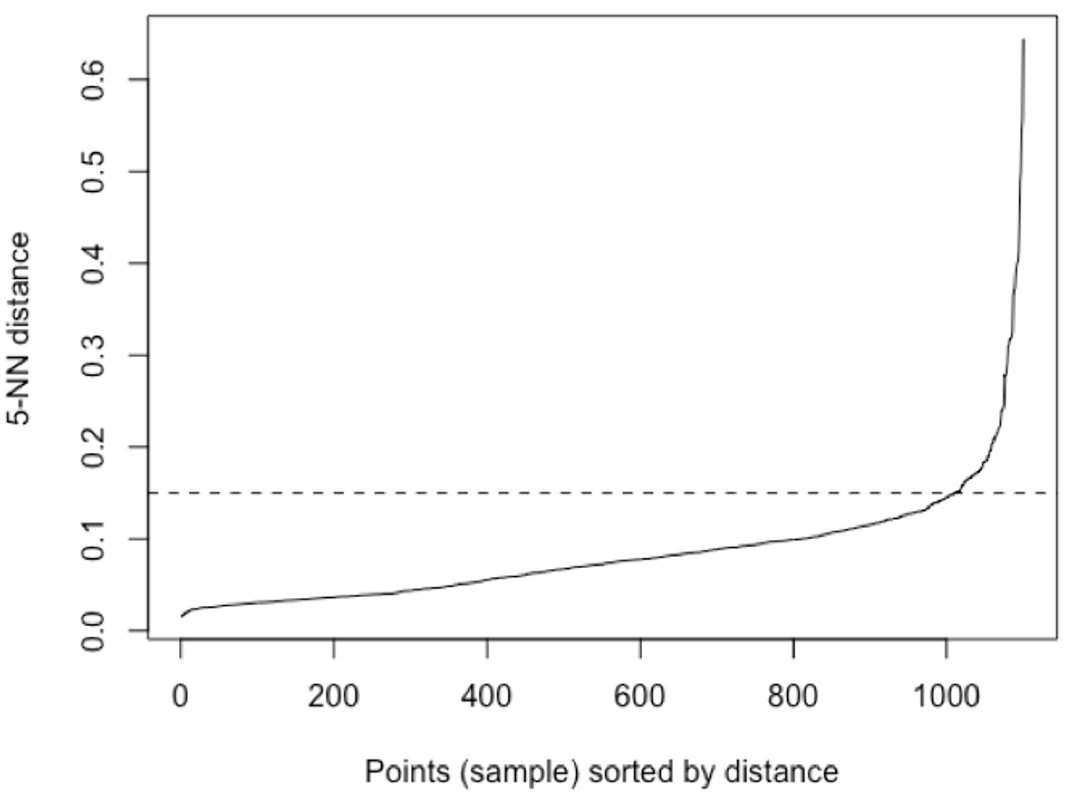
- 적절한 eps 설정:
- 적절한 eps 설정을 위해 KNN 알고리즘 을 활용할 수 있음.
- K를 (minPts-1)로 설정하여 모든 포인트에 대한 K개의 이웃 거리값을 오름차순으로 정렬한 그래프로 그림.
- 그래프에서 급격히 꺾이는 지점(elbow point)를 eps로 설정함.
DBSCAN 장단점
| 장점 | 단점 |
|---|
| 원형, 선형, 복잡한 형태의 클러스터도 잘 감지 | ε, minPts 설정에 민감함 |
| 노이즈 포인트를 별도로 분리 | 밀도가 다른 클러스터 처리 어려움 |
| K를 지정할 필요 없음 (KMeans와 다름) | 고차원에 부적합(거리기반 방식) |
Python 예시 코드
Scikit-learn 을 이용한 DBSCAN 실습 코드
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
X, _ = make_moons(n_samples=300, noise=0.05)
dbscan = DBSCAN(eps=0.2, min_samples=5)
labels = dbscan.fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=labels, cmap='rainbow')
plt.title("DBSCAN Clustering")
plt.show()
참고