딥러닝 학습과정에서 대표적으로 발생하는 문제인 기울기 소실과 폭주에 대한 정리
기울기 소실 (Vanishing Gradients)
개념 및 원인
- Gradient 라는 것이 결국 미분값 즉 변화량을 의미하는데 이 변화량이 매우 작아지거나(Vanishing) 커진다면(Exploding) 신경망을 효과적으로 학습시키지 못하고, Error rate 가 낮아지지 않고 수렴해버리는 문제가 발생함
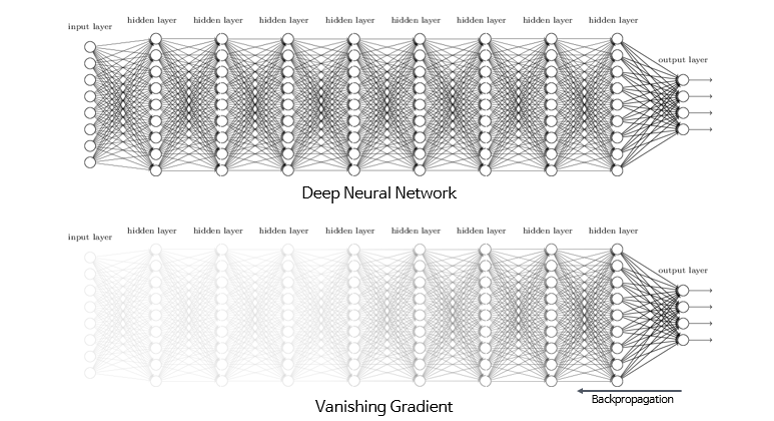
- 기울기 소실 (Vanishing Gradients)은 딥러닝 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 작아져 가중치들이 업데이트 되지 않아 최적의 모델을 찾을 수 없는 문제
- 레이어가 깊은 모델일수록 편미분 값들이 반복적으로 곱해지면서 기울기 소실문제를 야기함
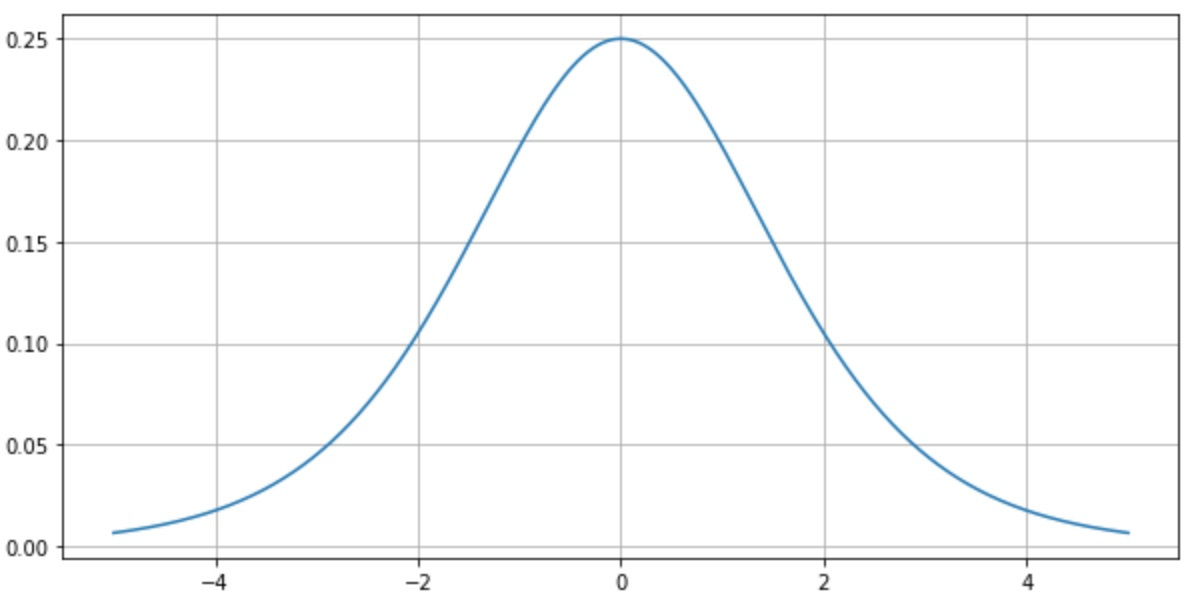
- 특히 활성화 함수로 sigmoid나 tanh를 사용하게 되면 편미분이 최대 0.25, 1의 값을 갖으며, 레이어가 깊어질수록 편미분 값들이 반복적으로 곱해지면서 1보다 작아지게 되고, 쉽게 기울기 소실을 야기함
- sigmoid 미분
기울기 소실 해결방법
Activation Function
- 활성화 함수가 적절한 기울기를 갖도록 해주어야 하는데, ReLU는 기울기가 1 or 0 이기 때문에 기울기 소실 문제를 해결할 수 있다.
- ReLU의 입력값이 양수일 때, 미분값은 항상 1 → 기울기 소실 문제 해결
- ReLU의 입력값이 음수일 때, 미분값은 항상 0 → 입력값이 음수인 뉴런은 회생불가(Dying ReLU) → Leaky ReLU 함수로 해결
Weight Initialization
- 같은 모델을 훈련시키더라도 가중치가 초기(최초)에 어떤 값을 가졌느냐에 따라서 모델의 훈련 결과가 달라지기도 하므로 가중치 초기화만 적절히 해줘도 기울기 소실 문제과 같은 문제를 완화시킬 수 있다.
- Xavier Initialization, He initialization 등의 방법을 사용해 가중치를 초기화하여 기울기 소실을 완화시킨다.
Batch Normalization
- 수렴하지 않는 활성화 함수를 이용하거나 가중치 초기화를 통해 기울기 소실이나 폭주를 완화시킬 수 있지만, 이 두 방법을 이용하더라도 훈련 중에 언제든 다시 기울기 소실이나 폭주가 발생할 수 있다.
- 배치정규화는 인공신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 입력분포를 일정하게 만들기 때문에 학습을 효율적으로 만들며 각 층에서 활성화 함수를 통과하기 전에 수행된다.
- 기울기 소실과 폭주의 발생확률을 낮출 수 있다.
기울기 폭주 (Exploding Gradients)
개념 및 원인
- 역전파 연산에는 Activation function의 편미분 값뿐만 아니라 가중치 값들도 관여하게 된다. 만약, 모델의 가중치들이 충분히 큰 값이라고 가정을 하면, 레이어가 깊어질수록 충분히 큰 가중치들이 반복적으로 곱해지면서 backward value가 폭발적으로 증가하며 이를 Exploding gradient라 한다.
- Vanishing gradient와 마찬가지로 Exploding gradient도 학습이 제대로 이루어지지 못하게 만든다.
기울기 폭주 해결방법
- ReLU의 경우 가중치가 충분히 크다면 backward value 값은 1보다 클 것이고, 반복적인 곱셈에 의해 backward value가 폭발적으로 증가할 것이다.
- 따라서 가중치에 규제를 주거나 기울기에 제한을 두어 기울기 폭주를 완화함.
Weight Decay (L2 Regularization)
- 가중치에 규제를 적용하여 가중치가 너무 큰 값을 가지지 않도록 한다.
- L1, L2 Regularization 등
Gradient Clipping
- 기울기의 값이 임계점을 넘지 않도록 제한을 두어 기울기가 너무 크지 않도록 한다.