CNN based Models : Xception 모델에 대한 정리
Xception 모델 개요
- Inception 모델의 Inception 모듈을 발전시켜 설계한 네트워크로서 마찬가지로 Google에서 발표함
- Xception은 완벽히 cross-channel correlations와 spatial correlations를 독립적으로 계산하기 위해 고안된 모델로, Depthwise Seperable Convolution의 개념을 활용한 Extreme Inception 구조를 제안함
- ResNet에서 제안한 Skip-Connection이 모든 흐름에 대해 배치됨
- 대부분의 고전적인 분류 문제에서 VGG-16, ResNet 및 Inception V3를 능가함
- Paper: Xception: Deep Learning with Depthwise Separable Convolutions
Inception Module의 해석
Convolution 해석
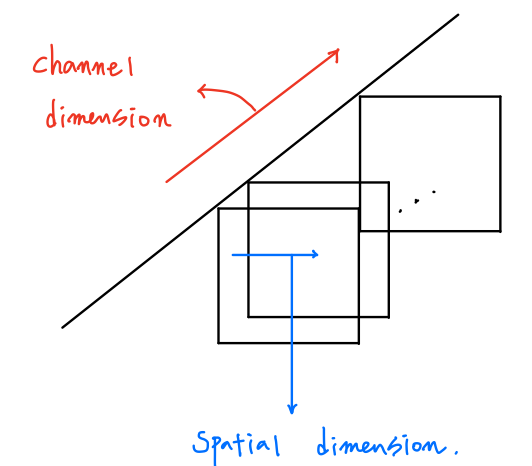
- CNN 모델의 입출력 데이터는 (H, W, C)의 구조로 3차원이라 볼 수 있다. 이는 Spatial dimension과 Channel dimension으로 나눠서 볼 수 있고, 그러므로 Conv 필터는 cross-channel correlation과 spatial correlation을 동시에 처리한다.
- 다시 말해, Conv 필터는 하나의 feature map의 상관관계를 구하는 것 (spatial correlation)과 여러 featue map간의 상관관계를 구하는 것 (cross-channel correlation)을 동시에 처리한다.
Inception module
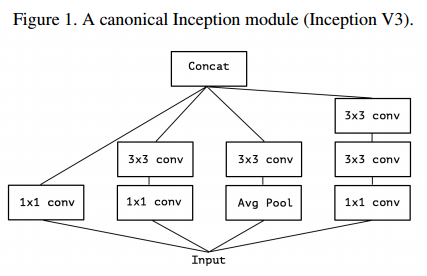
- 아래 그림은 Inception-V3에서 사용하는 Inception 모듈로, 하나의 입력이 여러 layer를 통과한 뒤 합쳐지는 구조를 가짐.
- 위 Convolution의 해석 관점에서 바라보면 Inception 모듈은 Cross-channel correlation과 Spatial correlation을 분리해서 처리가 가능하다고 볼 수 있다.
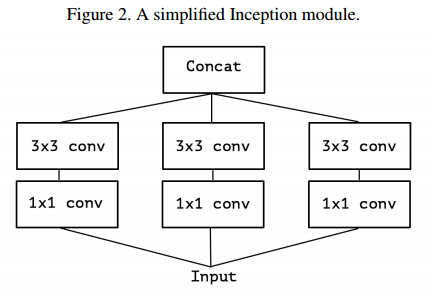
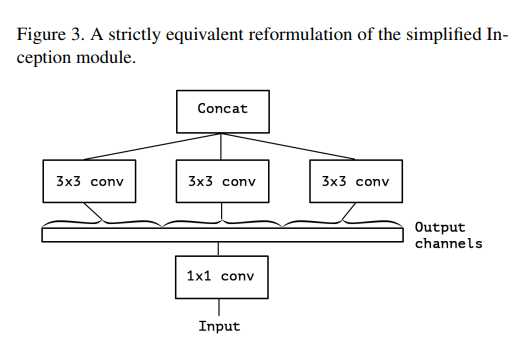
- 아래 그림은 Iception module을 단순화 한 것으로 1x1 conv 및 3x3 conv를 병렬로 처리하고 합치는 구조이다.
- 이때, 1x1 conv는 cross-channel correlation을 계산하고, 3x3은 spatial correlations를 수행한다. Inception 모듈이 좋은 성능을 나타내는 이유는 cross-channel correlations와 spatial correlations를 잘 분해해서 계산했기 때문이라고 해석함.
- 이러한 Inception 모듈의 가정을 유지한채 아래와 같이 1x1 conv를 하나로 합친구조를 만들 수 있다.
Depthwise Separable Convolution
- Xception에서 제안하는 Extreme Inception 모듈을 설명하기 전에 모듈의 기본이 되는 Depthwise Separable Convolution(DSC)에 대해 알아보자.
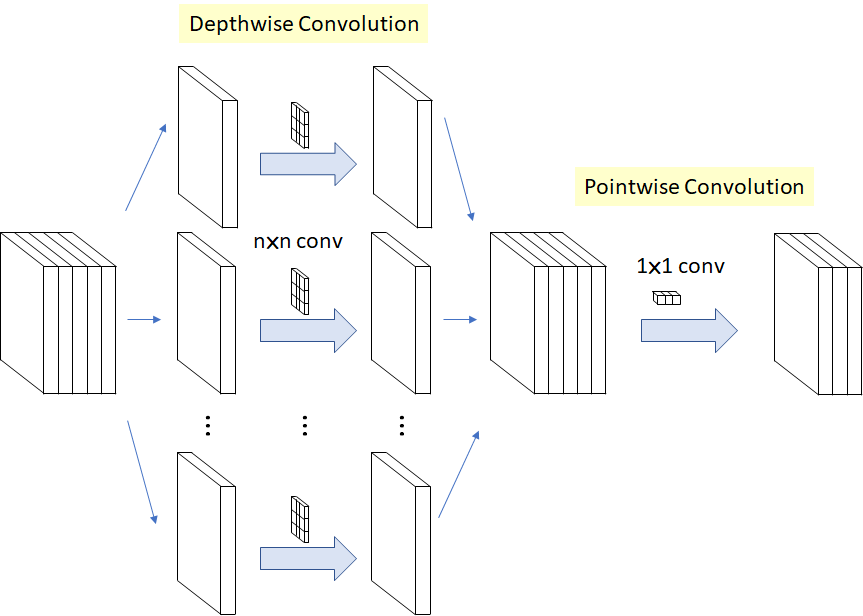
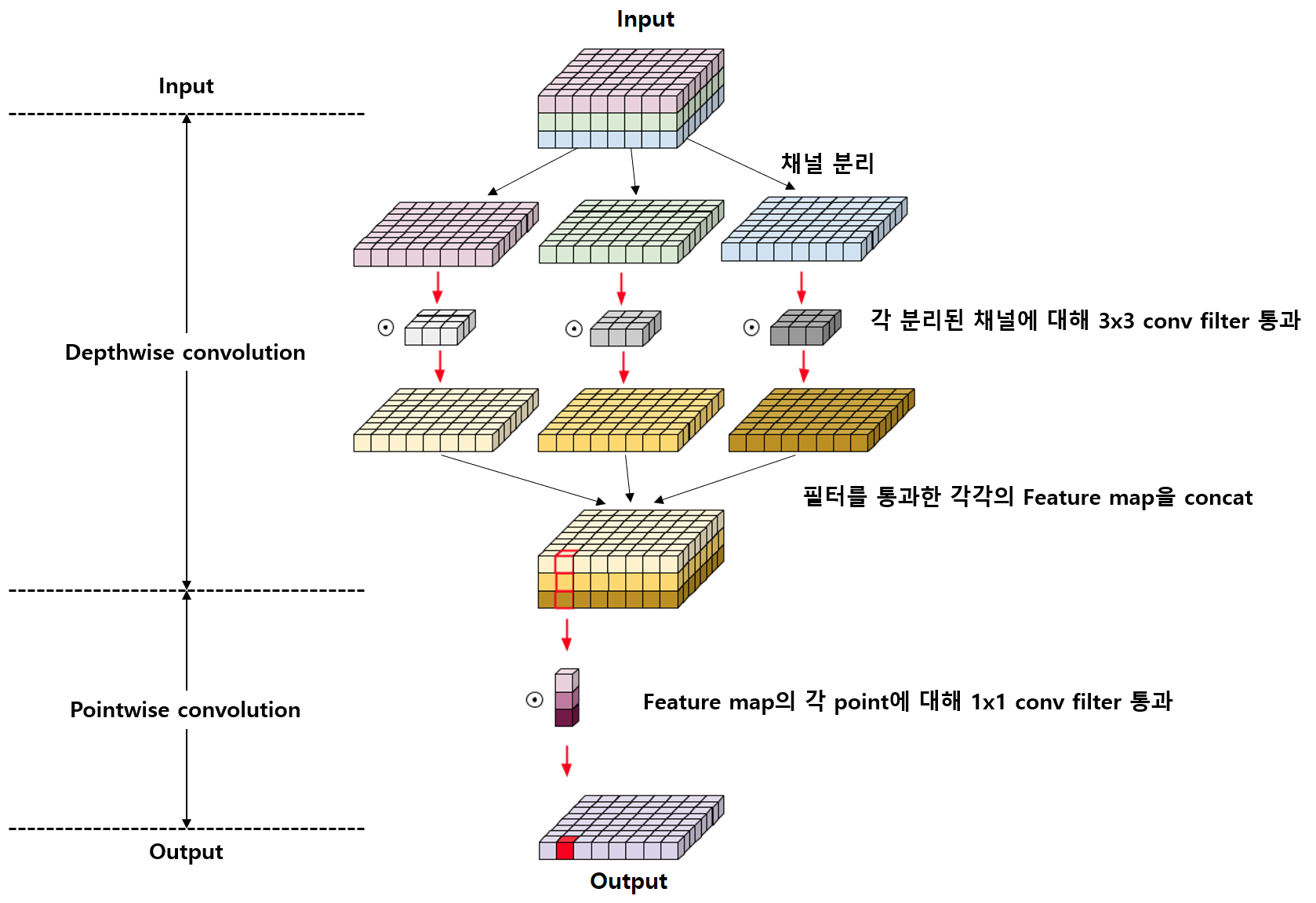
- DSC는 Depthwise convolution과 Pointwise convolution으로 이루어짐.
Depthwise Convolution
- 채널과 관계없이 spatial convolution을 진행함
- 필터를 채널의 개수만큼 준비하고, 각 채널마다 하나의 필터가 컨볼루션됨
- 따라서 필터 수는 입력 채널의 수와 동일하고, 완벽히 각 채널의 spatial 특징만 추출할 수 있다.
Pointwise Convolution
- 단순히 1x1 Convolution을 말하며 입력의 채널을 늘리거나 줄이거나하며 변형하는 역할로 사용됨
Original Depthwise Separable Convolution
- Depthwise Convolution을 수행 후 Pointwise Convolution을 수행함
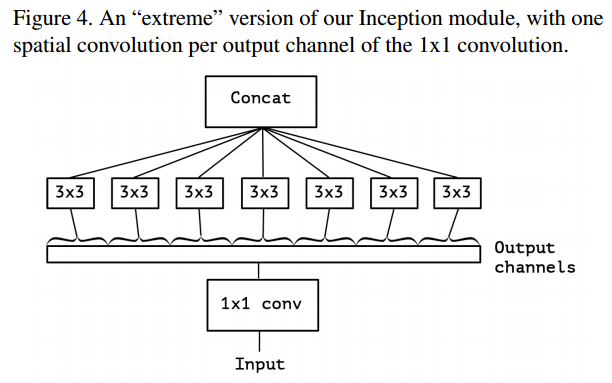
eXtreme Inception
extreme Inception
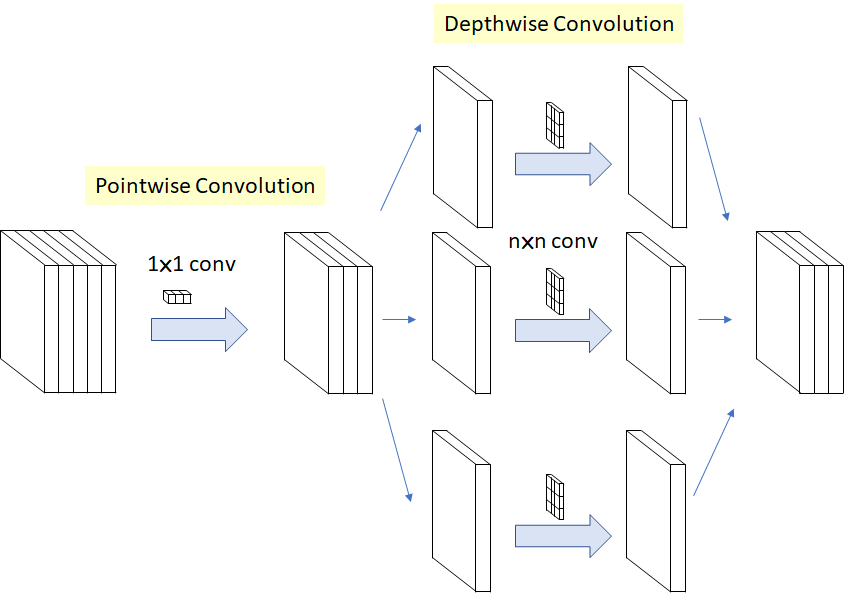
- Depthwise Separable Convolution 구조를 수정하여 extreme Inception 구조를 제안함.
- 두 방향(channel wise, spatial)에 대한 mapping을 완전히 분리하기 위해, input에 대해 1x1 convolution을 거친 후에, 모든 channel을 분리시켜서 output channel당 3x3 convolution을 해준다.
DSC와 차이
- extreme Inception 모듈은 DSC를 수정하여 고안되었으므로, 두 방법은 유사하지만 사소한 차이점이 존재함
- Depthwise conv와 Pointwise Conv의 순서가 반대로 되어있음
- extreme Inception은 채널 수를 먼저 줄이고, 각 채널에 대한 공간 컨볼루션을 진행함
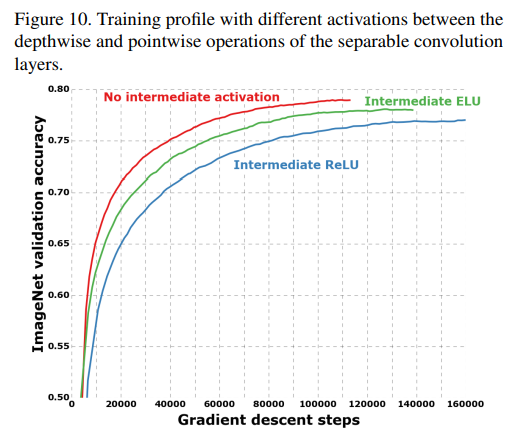
- 비선형함수의 사용 유무
- 오리지널 Inception 모듈의 경우 pointwise/depthwise convolution을 각각 수행 후 ReLU등을 추가해 비선형성을 추가하지만, DSC를 사용하는 extreme Inception은 depthwise conv와 pointwise conv 사이에 ReLU가 없음
- 이는 비선형 함수가 있을 때 보다 더 좋은 성능을 보임
- ReLU와 같은 비선형 활성함수는 깊은 feature space에서는 유용하지만 1개 채널 feature space와 같이 얕은 feature space에서는 정보의 손실을 야기하기 때문에 오히려 악영향을 끼친것으로 추정함
Xception 모델 구조 및 성능
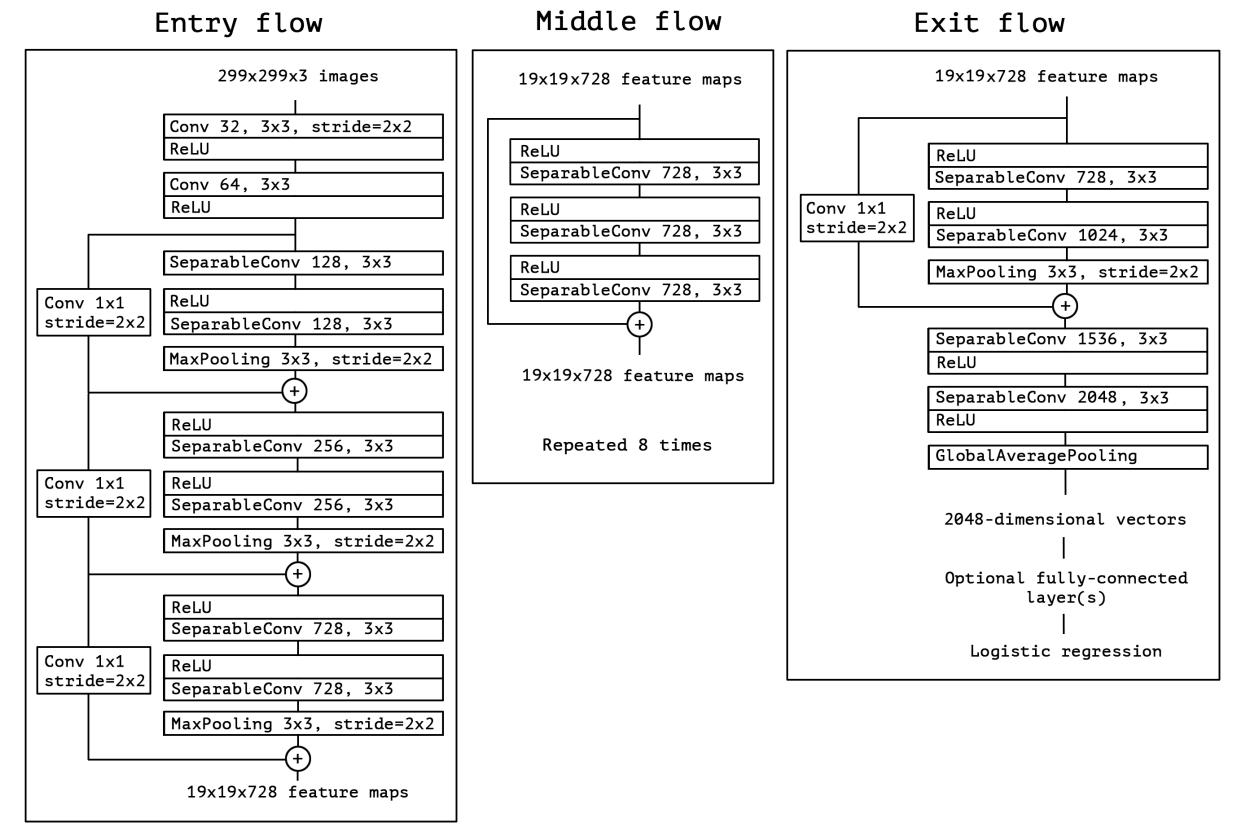
모델 구조
- Xception은 14개의 모듈, 36개 convolution layer로 구성되었으며 첫 번째 conv layer와 마지막 conv layer를 제외하고는 모두 residual connection으로 연결된 구조.
성능 평가
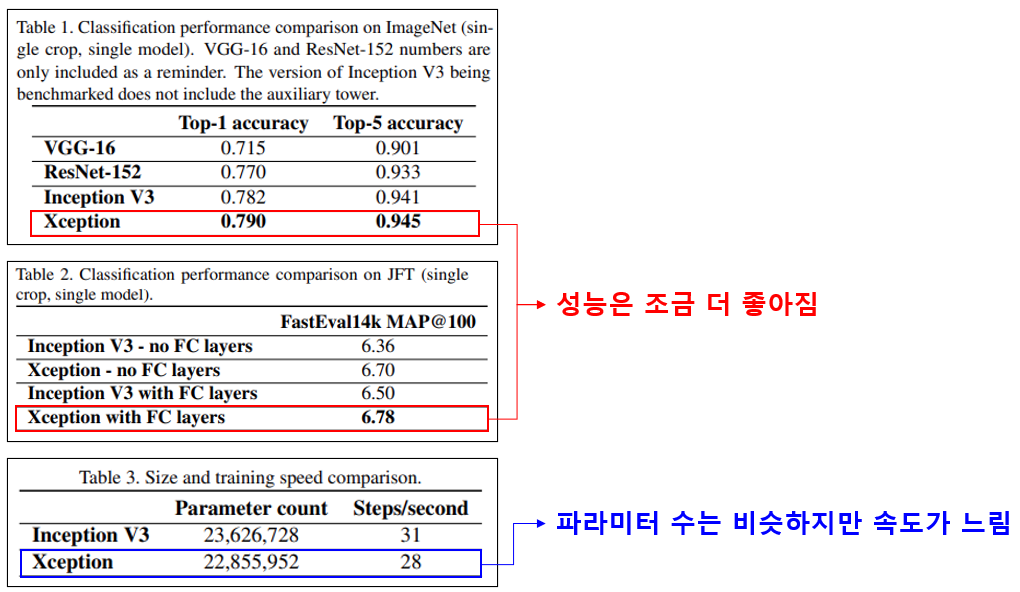
- Xception을 ImageNet dataset과 Google의 내부 데이터인 JFT dataset에 대해 분석한 결과 이전에 발표된 모델들보다 xception 이 조금 더 좋은 성능을 보여줌.
- 제일 아래 결과에서 Inception v3와 파라미터 수는 거의 유사하지만, 각 단계에서 동작속도가 느려졌습니다. 논문에서는 그 이유로 depthwise separable convolution구조를 연산할 때 최적화가 덜 된것을 원인으로 추정했으며 미래에 개선될 것이라고 주장함.
- 주목할 점은 Xception이 유사한 수의 파라미터를 가지고 성능을 향상시켰다는 점. 논문에서는 이 결과를 Xception의 성능향상이 파라미터를 추가해서가 아닌 파라미터를 더 효율적으로 사용함으로 써 이루어냈다는 의미로 해석함